Para los humanos hacer un juicio comparativo (por ejemplo, \(A\) es mayor que \(B\)) es más fácil de realizar que un juicio absoluto (\(A = 1.72\)\(m\) y \(B = 1.69\)\(m\)), si lo único con lo que se cuenta para hacer el juicio es la propia percecpción de las cosas. Esto se debe a que mientras en un juicio absoluto un estímulo es puesto en una categoría particular, en un juicio comparativo dos o más estímulos son comparados entre ellos o contra un estímulo estándar (APA, 2022).
Las ventajas del juicio comparativo no sólo son su practicidad, sino que incluso las severidades individuales de los jueces que hacen los juicios comparativos o relativos se eliminan experimentalmente, es decir, no importa qué tan buenos (en términos absolutos) piensen que son las cosas que están juzgando, ya que todo lo que importa es su mérito relativo (Bramley, s.f.). Por otro lado otra de las ventajas del método es que puede manejar información faltante, debido a que la escala de separación entre cualquiera dos objetos no depende de los otros objetos con los que fueron comparados (Bramley, s.f.).
Modelo
El modelo de elección de Thurston de 1927 fue uno de los primeros modelos probabilísticos propuestos, también llamado modelo probit. Este en un inicio fue aplicado al área de psicofísica, pero después aplicó su modelo a un amplio rango de problemas incluyendo la elección preferencial (Busemeyer y Wang, 2021). De hecho, uno de sus grandes logros fue librar los juicios psicofísicos de estar restringidos a atributos de estímulos que tienen una magnitud física medible y desarrollar una teoría de medición psicológica (medición subjetiva) para atributos no físicos (por ejemplo, seriedad de un crimen).
En un inicio el modelo de Thurston se diseñó para la comparación de dos estímulos, aunque actualmente hay variantes que consideran tres o más estímulos. En este simulador sólo se considerará el modelo inicial y en particular el Caso V, que es el más sencillo y se explicará más adelante.
Elementos clave del modelo:
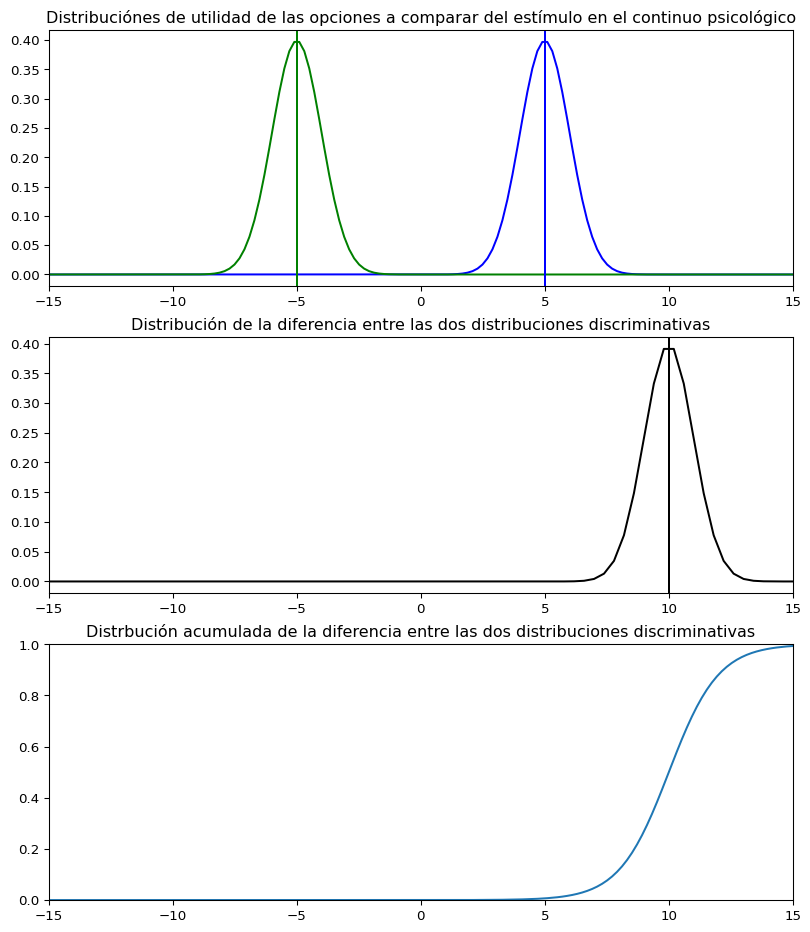
Dispersión discriminativa: Existe una distribución de frecuencias de utilidad con el que un estimulo es asociado con un proceso particular de discriminación y se considera que la distribución corresponde a una Normal. Es importante notar que si se tiene dos opciones a comparar entonces cada opción tendrá su propia distribución, donde la moda de cada distribución define la localización (el valor esperado de utilidad de una opción) del estímulo en el continuo psicológico y la desviación estándar define una arbitraria unidad de medida. Por su parte, la varianza de las utilidades respresenta un tipo de incertidumbre que una persona puede tener dada una opción. Finalmente, la covariaza entre ambas distribuciones captura los efectos contextuales producidos por la similaridad entre el par de opciones y la distancia entre la moda de las dos distribuciones corresponde a la escala de separación del estímulo (Bramley, s.f.; Busemeyer y Wang, 2021).
Ley del jucio comparativo: La moda discriminativa y la dispersión que corresponde a un solo estímulo es inaccesible a la observación, ya que estas propiedades sólo pueden ser estimadas cuando dos objetos son comparados, dado que el objeto que evoca el proceso discriminativo será juzgado como poseedor de mayor o menor cantidad del atributo.
Es así que el juicio de comparación está relacionado con la distribución de la diferencia entre las dos distribuciones discriminativas (una del objeto \(A\) y otra del objeto \(B\)), donde la media de la nueva distribución será la diferencia entre las medias de la anterior distribución (Bramley, s.f.).
Interpretación:
Si la diferencia es positiva (mayor a \(0\)), entonces se tiene un juicio donde A tiene más del atributo a evaluar que \(B\). Como resultado, la parte de la curva de la distribución que sea mayor a \(0\) es igual a la probabilidad de \(A>B\).
Si la diferencia es negativa (menor que \(0\)), entonces se tiene un juicio donde B tiene más del atributo a evaluar que \(A\). Como resultado, la parte de la curva de la distribución que sea menor a \(0\) es igual a la probabilidad de \(B < A\).
Características del caso V del modelo de Thurston
Se tiene una opción binaria (mayor o menor) entre un par de opciones (A, B).
Cada opción tienen la misma varianza en su distribución característica.
Todas las variables aleatorias están no correlacionadas.
Se condidera una desviación estándar igual a 1 para cada distribución.
Simulador
Las variables mu1 y mu2 representan la media de la distribución 1 (azul) y la distribución 2 (verde), respectivamente.
Haz Clic para ver el Código
```{python}import matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport scipy.stats as statsimport scipyfrom scipy import linalgimport mathfrom scipy.stats import logisticdef comp_j( mu1, mu2): mu_1 = mu1 mu_2 = mu2 variance =1 sigma = math.sqrt(variance) x = np.linspace(mu_1 -20*sigma, mu_1 +20*sigma, 200) x_2 = np.linspace(mu_2 -20*sigma, mu_2 +20*sigma, 200) mu_3 = mu_1 - mu_2 x_3 = np.linspace(mu_3 -40*sigma, mu_3 +40*sigma, 200) fig, (ax1, ax2, ax3) = plt.subplots(3, figsize=(10, 12)) ax1.plot(x, stats.norm.pdf(x, mu_1, sigma), color="blue") ax1.plot(x_2, stats.norm.pdf(x_2, mu_2, sigma), color="green") ax1.title.set_text('Distribuciónes de utilidad de las opciones a comparar del estímulo en el continuo psicológico') ax2.plot(x_3, stats.norm.pdf(x_3, mu_3, sigma), color="black") ax2.title.set_text('Distribución de la diferencia entre las dos distribuciones discriminativas') y = logistic.cdf(x, mu_3, 1) ax3.plot(x, y) ax3.title.set_text('Distrbución acumulada de la diferencia entre las dos distribuciones discriminativas')#ax2.fill_between(x_3, stats.norm.pdf(x_3, mu_3, sigma), facecolor = 'black', where=x>0) ax1.axvline(x = mu_1, color ='blue', label ='axvline - full height') ax1.axvline(x = mu_2, color ='green', label ='axvline - full height') ax2.axvline(x = mu_3, color ='black', label ='axvline - full height') ax1.set_xlim(left=-15, right=15) ax2.set_xlim(left=-15, right=15) ax3.set_xlim(left=-15, right=15) ax3.set_ylim(0,1) plt.show()comp_j(mu1 =5, mu2 =-5)```
Ejercicios
Varía los valores de las variables mu1 y mu2 moviendo los y observa cómo cambian las tres gráficas del simulador. Después, ttrata de responder las siguientes preguntas:
¿Qué pasa con las diferentes gráficas cuando mu1 = 3 = mu2?
¿Qué pasa con las diferentes gráficas cuando mu1 es mayor a mu2?
¿Qué pasa con las diferentes gráficas cuando mu1 es mayor a mu2?