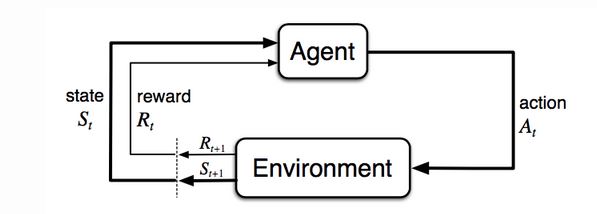
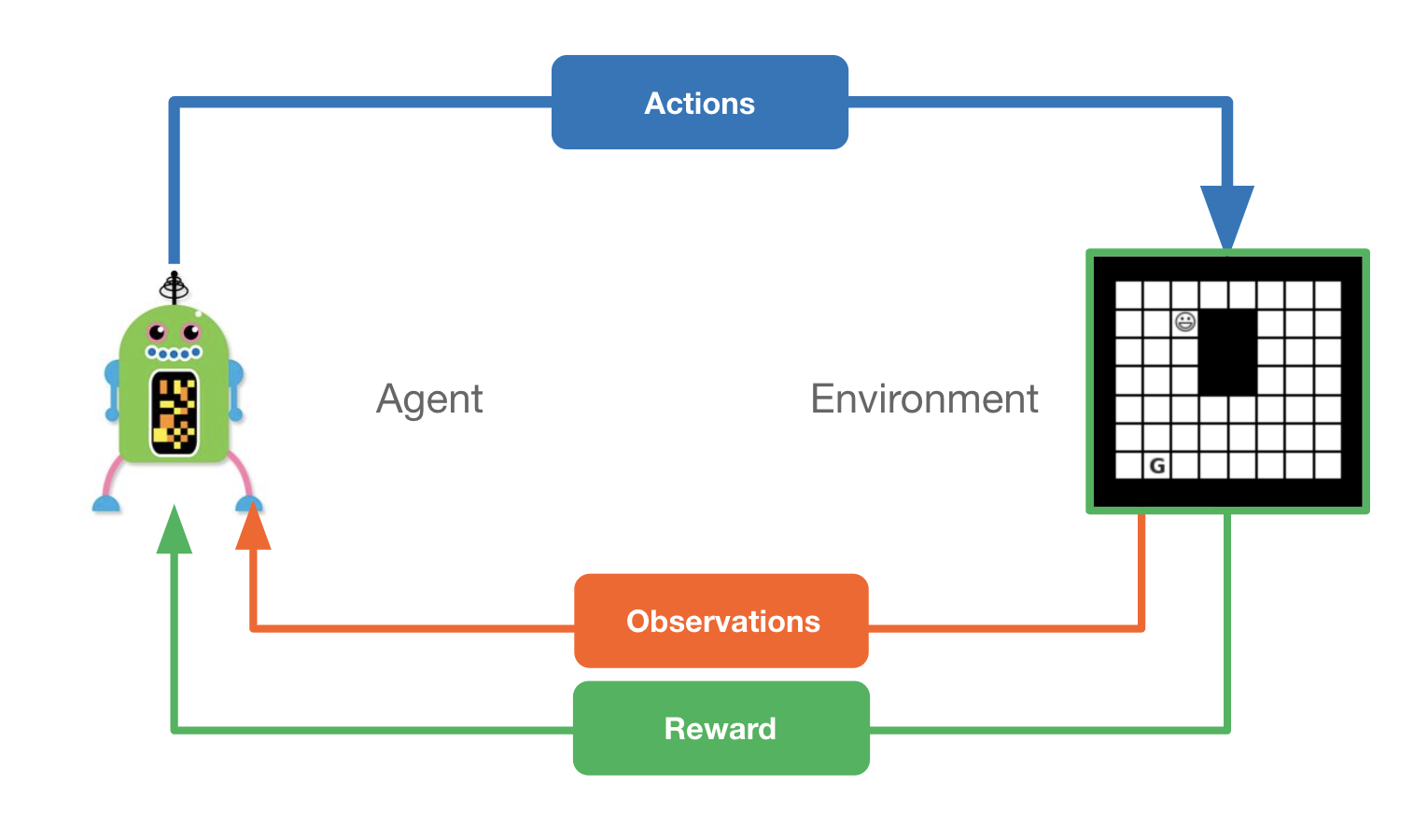
Imaginemos que hay un organismo o agente en un entorno desconocido, que este entorno tiene diferente tipo de consecuencias dependiendo de la interacción del agente con su entorno. Y que el objetivo final del agente es maximizar sus recompensas cumulativas. El aprendizaje por refuerzo es el poder aprender una estrategia efectiva para completar el objetivo por medio de prueba y error, feedback.
Muchos de los conceptos principales se construyen de temas básicos como procesos de decisión Markovianos y el dilema de exploración-explotación.
Procesos de decisión Markovianos
Casi todos los problemas de aprendizaje por refuerzo pueden ser conceptualizados como un problema Markoviano de decisión. ¿a que nos referimos con esto? una propiedad “Markoviana” que todos nuestros estados deben de tener es el hecho de que el futuro depende del estado actual no de toda la historia.
Que el futuro y el pasado con condicionalmente independientes según el presente, o que en el estado actual tenemos todo lo necesario para tomar una decisión futura.
Un proceso Markoviano tiene 5 elementos que son los siguientes:
\(\color{red}{S}\) - un set de estados
\(\color{blue}{A}\) - un set de acciones
\(\color{yellow}{P}\) -una función de probabilidad que determina la transición
\(\color{green}{R}\) -una función de recompensa
\(\gamma\) - un factor de descuento para las recompensas futuras
Se incluye un ejemplo:
El dilema de exploración-explotación es un dilema que existe en muchas facetas de nuestra vida.Tomemos un ejemplo comunmente usado respecto a las posibles parejas que podríamos tener en nuestra vida y cuando sería el momento apropiado para “sentar cabeza”. Si tienes una pareja por mucho tiempo ya sabes el tipo de interacción que tienes, o la cantidad de momentos agradables vs problemas, que tienes con esta. Sin embargo, si cambias constantemente de pareja realmente no conoces del todo esta nueva persona, no sabes bien el tipo de interacción y lo bien o mal que te puedas llevar con estas parejas desconocidas. Sin embargo, el dilema consiste en como saber que la pareja con la que estas es la mejor opción y como saber cuando es tiempo de dejar de buscar otras parejas y elegir alguna. En esto consiste el dilema. Trasladandolo al campo de inteligencia artifical, si has aprendido toda la información acerca del ambiente, si sabemos absolutamente todas las parejas disponibles y el valor de cada una, la decisión es sencilla,solo tomar la de mayor valor. El problema existe cuando se tiene información incompleta, y necesitamos recolectar suficiente información para poder maximizar la recompensa y minimizar el riesgo. Una forma de cuantificar y hacer experimentación en el campo se refiere a los “bandidos”, que basicamente son máquinas al ser usadas tienen una cierta probabilidad para dar una cierta recompensa, el paradigma consiste en que el tiempo es limitado y solo puedes usar 1 en cada momento. La pregunta es: ¿Cual es la mejor estrategia para maximizar las recompensas?
Si tenemos a un agente que debe seleccionar que maquina usar. Lo primero que el agente debe de decidir es cual escoger.Aunque podriamos solo elegir aleatoriamente, queremos tener alguna creencia que justifique o describa cada decisión.Esto en la literatura se ejemplifica con el uso de una politica determinada por \(\color{blue}{\pi}\). También se necesita una función de valor por cada acción, al valor se le conoce como valor \(\color{green}{Q}\) . El valor \(\color{green}{Q}\) por tomar la acción \(\color{blue}{a \in A}\) en un tiempo determinado como \(t\) que no dará el valor de la recompensa en este tiempo \(r_t\) dada la acción elegida \(\color{blue}{a}\) . La fórmula es la siguiente:
Pero retomando lo aprendido acerca del dilema de exploración-exploración, si siempre tomamos la opción de mayor valor no sabemos bien cual es el valor del resto de las opciones o ¿de que nos estamos perdiendo? La solución más común a este problema es agregar un poco de aletoriedad al modelo. Determinar una probabilidad en la que se toma una acción diferente a la que tiene el valor máximo. Normalmente a esta estrategia se le llama “epsilon greedy”, que indica que 1 - \(\epsilon\) para \(\epsilon \in [0,1]\) seleccionamos la opción con mayor valor o “greedy”, en caso contrario con una probabilidad pequeña \(\epsilon\) elegimos una acción aleatoriamente (incluyendo la opción con mayor valor)
Otro concepto importante es REGRET , o “arrepentimiento”, básicamente es que tanto nos arrepentimos de seleccionar la acción elegida y no la opción optima en ese momento. Matematicamente la identificamos como:
Existen varios acercamientos básicos que por falta de tiempo evitare exponer en esta libreta, pero que son la base de acercamientos un poco más complejos. Cuando nos referimos a términos como \(basado\)\(en\)\(modelos\), nos referimos a que existe un modelo del ambiente, que podemos conocer el ambiente o que se crea un modelo del ambiente dado el algoritmo. El término \(libre\)\(de\)\(modelo\) nos indica que no hay una dependencia en un modelo durante en el aprendizaje. También existen algoritmos \(en\)\(politica\) o \(sin\) politica, que determinan si el algoritmo va a usar outputs determinados de una función o samples de una política para el aprendizaje que sería el caso en los algoritmos \(on\)\(policy\), por otra parte los \(off\)\(policy\) se entrenan en una distribución de transiciones o episodios producidos por una política de comportamiento en lugar de la política optima objetivo.
Ahora que tenemos una política para tomar decisiones a cada momento, hablaremos de como podemos aprender de las recompensas de cada una de las acciones. Recordamos que tenemos una función de valor-acción llamada función Q, asociada con seguir una cierta politica \(\pi\) en un proceso de decisión Markoviano como:
donde \(\tau = \{\color{red}{s_0}, \color{blue}{a_0}, \color{green}{r_0}, \color{red}{s_1}, \color{blue}{a_1}, \color{green}{r_1}, \cdots \}\) Recordando la propiedad Markoviana que explica que el siguiente estado depende solo del estado actual y no en todos los estados que vinieron antes de el.
Tomando como el objetivo del agente, o el \(Goal\) es el maximizar la suma de las recompensas futuras \(descontadas\)\(\gamma\) especifica que tanto van a valer las recompensas futuras comparadas con la recompensa actual. Mientras que la politica mapea estados a acciones.
Las ecuaciones de Bellman son un set de ecuaciones que descomponen el valor de la acción, en el valor actual junto con los valores descontados futuros. \[ \begin{aligned} V(s_t) &= \mathbb{E}_t[G_t \vert S_t = s] \\ &= \mathbb{E}_t [r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \dots \vert S_t=s] \\ &= \mathbb{E}_t [r_{t+1} + \gamma (R_{t+2} + \gamma r_{t+3} + \dots) \vert S_t = s] \\ &= \mathbb{E}_t [r_{t+1} + \gamma G_{t+1} \vert S_t = s] \\ &= \mathbb{E}_t [r_{t+1} + \gamma V(S_{t+1}) \vert S_t = s] \end{aligned} \]
donde \(\color{green}V^{\color{blue}{\pi}}\) es el valor \(\color{green}Q^{\color{blue}{\pi}}\) esperado para un estado particular \(\color{green}V^{\color{blue}{\pi}}(\color{red}{s}) = \sum_{\color{blue}{a} \in \color{blue}{\mathcal{A}}} \color{blue}{\pi}(\color{blue}{a} |\color{red}{s}) \color{green}Q^{\color{blue}{\pi}}(\color{red}{s},\color{blue}{a})\).
Ahora tendremos que repasar el principio de optimalización de Bellman. Que nos indica que el valor de un estado con una política optimizada es igual a la recompensa esperada de la mejor acción de ese estado.
Principio de optimización de Bellman\[\begin{equation}
\color{green}{V}^{\color{green}{*}}(\color{red}{s},\color{blue}{a}) =
\max_{\color{blue}{a'}} \color{green}{Q^{*}}(\color{red}{s'},\color{blue}{a'})
\end{equation}\]\[\begin{equation}
\color{green}{Q}^{\color{green}{*}}(\color{red}{s},\color{blue}{a}) = \color{green}{R}(\color{red}{s},\color{blue}{a}) +\gamma \sum_{\color{red}{s'}\in \color{red}{\mathcal{S}}}
\color{purple}{P}(\color{red}{s'} |\color{red}{s},\color{blue}{a})\end{equation}\] La política optima se obtiene maximizando la función de acción-estado. Se dice que la política es greedy con respecto de la función de valor optimo. \[\begin{equation}
\color{blue}{\pi}^{\color{green}{*}}(\color{red}{s},\color{blue}{a}) =
\max_{\color{blue}{a'}} \color{green}{Q^{*}}(\color{red}{s'},\color{blue}{a'})
\end{equation}\]
Y si solo estamos interesados en los valores optimos, sin tener en cuenta la expectativa de seguir una política podríamos solamente usar los valores máximos sin usar una política. Los valores óptimos \(V^*\) y \(Q^*\) son los mejores que podemos obtener.
Si tenemos información compelta de el ambiente, esto se convierte en un problema de planeación. Sin embargo, no siempre tenemos las probabilidades de cada acción dado los estados ni la cantidad de refuerzo dado el estado y la acción, por lo tanto no podemos solo aplicar las ecuaciones y tomarlo como un proceso de decisión Markoviano. Pero es una parte importante de las formas de solucionar estos problemas.
Iteración de política vs iteración de valor:
Iteración de política (usando la ecuación de Bellman)\[\begin{equation}
\color{green}{Q}_{\color{green}{k}}(\color{red}{s},\color{blue}{a}) \leftarrow \color{green}{R}(\color{red}{s},\color{blue}{a}) +\gamma \sum_{\color{red}{s'}\in \color{red}{\mathcal{S}}}
\color{purple}{P}(\color{red}{s'} |\color{red}{s},\color{blue}{a})
\sum_{\color{blue}{a'} \in \color{blue}{\mathcal{A}}} \color{blue}{\pi_{k-1}}(\color{blue}{a'} |\color{red}{s'}) \color{green}{Q_{k-1}}(\color{red}{s'},\color{blue}{a'})
\end{equation}\]
Iteración de valor(usando la ecuación de optimalización de Bellman)\[\begin{equation}
\color{green}{Q}_{\color{green}{k}}(\color{red}{s},\color{blue}{a}) \leftarrow \color{green}{R}(\color{red}{s},\color{blue}{a}) +\gamma \sum_{\color{red}{s'}\in \color{red}{\mathcal{S}}}
\color{purple}{P}(\color{red}{s'} |\color{red}{s},\color{blue}{a})
\max_{\color{blue}{a'}} \color{green}{Q_{k-1}}(\color{red}{s'},\color{blue}{a'})
\end{equation}\]
El \(aprendizaje\)\(por\)\(diferencia\)\(temporal\) temporal o Temporal Difference Learning es un algoritmo libre de modelos, que puede aprender de la experiencia de cada episodio, pero no necesariamente episodios completos pero de igual manera de episodios, esto se le llama “bootstrapping”. El algoritmo actualiza los objetivos con respecto a estimados actuales en lugar de solo la recompensa actual y la recompensa total. La idea principal de este algoritmo es que vamos a actualizar la función de valor hacia una recompensa estimada, u “objetivo” determinada por \(R_{t+1} + \gamma V(S_{t+1})\) el valor que le damos a el objetivo esta controlado por el “learning rate” identificado por el signo \[ \begin{aligned} V(S_t) &\leftarrow (1- \alpha) V(S_t) + \alpha G_t \\ V(S_t) &\leftarrow V(S_t) + \alpha (G_t - V(S_t)) \\ V(S_t) &\leftarrow V(S_t) + \alpha (R_{t+1} + \gamma V(S_{t+1}) - V(S_t)) \end{aligned} \] y nuestra estimación de acción-valor quedaría como: \[ Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha (R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t)) \]
Sarsa vs Qlearning:
SARSA
Sarsa es un algoritmo que recibe su nombre gracias al proceso de actualizar el valor Q usando una secuencia de \(S_t\),\(A_t\),\(R_{t+1}\),\(S_{t+1}\),\(A_{t+1}\)… El algoritmo es el siguiente:
1.- Se iniciliza t=0
2.- Se inicia con el estado \(S_0\) y se escoge la acción \[A_0= \arg\max_{a \in \mathcal{A}} Q(S_t, a)\]; ε-greedy normalmente es aplicada
3.-En el tiempo \(t\), despues de aplicar la acción \(At\), se obtiene \(R_{t+1}\) y se llega al estado $S_{t+1}
4.- Se selecciona la siguiente acción de la misma forma que en el paso 2 \[A_{t+1}= \arg\max_{a \in \mathcal{A}} Q(S_t, a)\]
5.- Se actualiza la función del valor de Q de acuerdo a la siguiente fórmula: \[ Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha (R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t)) \].
o escrito de otra forma: \[\begin{equation}
\color{green}Q(\color{red}{s},\color{blue}{a}) \leftarrow \color{green}Q(\color{red}{s},\color{blue}{a}) +\alpha(\color{green}{r} + \gamma\color{green}{Q}(\color{red}{s'},\color{blue}{a'}) - \color{green}{Q}(\color{red}{s},\color{blue}{a}))
\end{equation}\]
6.- t=t+1 y se repite desde el paso 1
Q-LEARNING Es un algoritmo que no necesita una política y que aprende antes de que se acabe el episodio. El algoritmo es el siguiente:
1.- Se iniciliza t=0
2.- Se inicia con el estado \(S_0\)
3.-En el tiempo \(t\), despues de aplicar la acción \(A_t= arg max Q(S_t,a)\) con ε-greedy
4.- Se obtiene \(R_{t+1}\) y se llega al estado \(S_{t+1}\)
5.- Se actualiza la función del valor de Q de acuerdo a la siguiente fórmula: \[ Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha (R_{t+1} + \gamma \max_{a \in \mathcal{A}} Q(S_{t+1}, a) - Q(S_t, A_t)) \] o escrito de otra forma: \[\begin{equation}
\color{green}Q(\color{red}{s},\color{blue}{a}) \leftarrow \color{green}Q(\color{red}{s},\color{blue}{a}) +\alpha(\color{green}{r} + \gamma\max_{\color{blue}{a'}} \color{green}{Q}(\color{red}{s'},\color{blue}{a'}) - \color{green}{Q}(\color{red}{s},\color{blue}{a}))
\end{equation}\]
6.- t=t+1 y se repite desde el paso 3
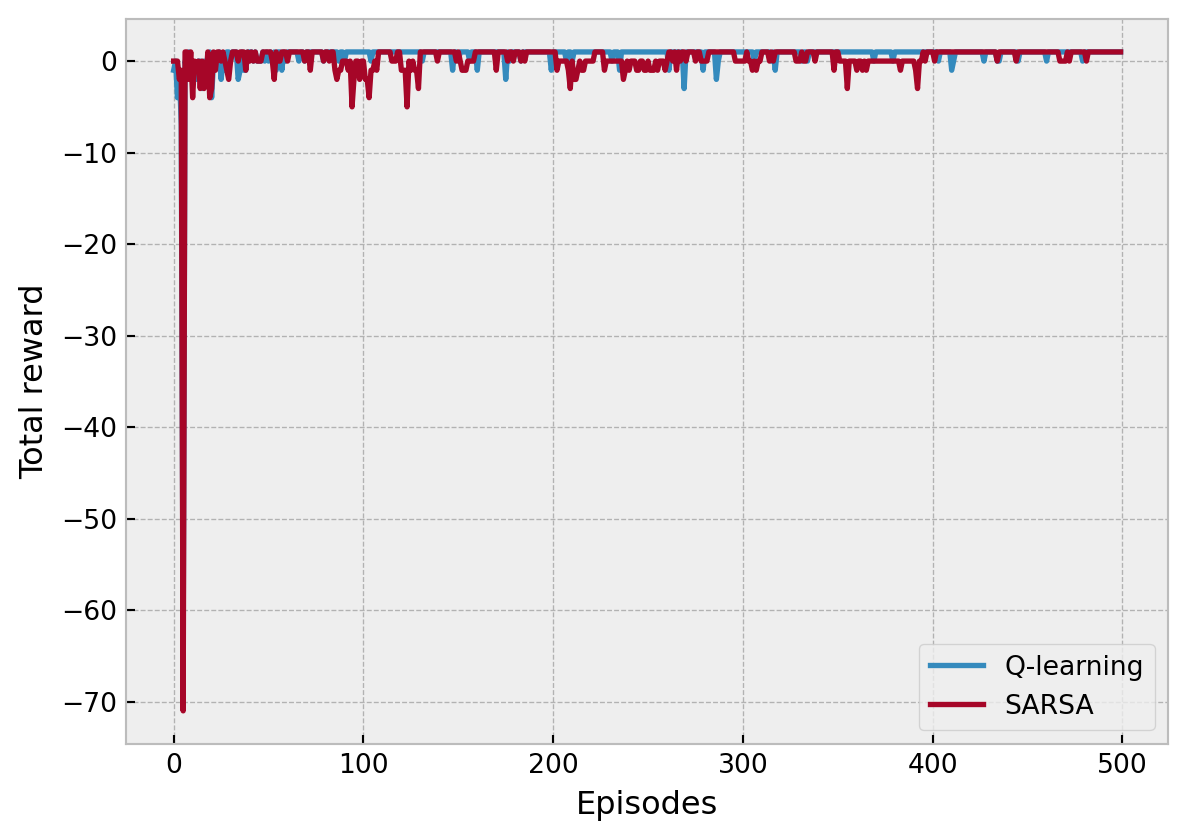
La diferencia principal entre Sarsa y Q-learning es que Q-learning no sigue la política actual para elegir la segunda acción \(A_{t+1}\). Estima la \(Q_*\) de acuerdo a los mejores valores de Q, pero cual acción \(a_*\) dirige al máximo Q. Sin importar la política actual.
Ahora implementaremos todos los algoritmos que hemos aprendido en un ambiente donde un agente tenga que tomar decisiones y pueda recibir consecuencias por sus acciones.
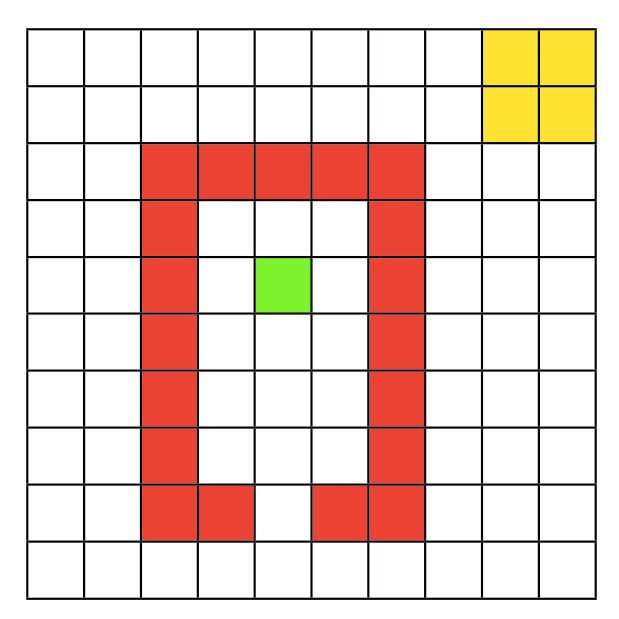
Ambiente Quentin’s World
Usaremos el ambiente llamado Quentin World.
Para este ambiente tenemos 100 estados y acciones posibles, desplazarse a cada uno de los cuadros contiguos a cada momento. El agente inicia en el cuadro verde, los cuadros rojos dan una recompensa negativa, no se puede salir del gridworld y moverse al cuadro amarillo le dará una recompensa. En este ambiente usaremos SARSA y Q-learning, además de unos algoritmos más avanzados y nuevos.
Inicializamos el ambiente y sus restricciones.
Haz Clic para ver el Código
```{python}#Primero inicializamos el ambiente y codificamos sus restriccionesclass world(object):def__init__(self):returndef get_outcome(self):print("Abstract method, not implemented")returndef get_all_outcomes(self): outcomes = {}for state inrange(self.n_states):for action inrange(self.n_actions): next_state, reward =self.get_outcome(state, action) outcomes[state, action] = [(1, next_state, reward)]return outcomesclass QuentinsWorld(world):def__init__(self):self.name ="QuentinsWorld"self.n_states =100self.n_actions =4self.dim_x =10self.dim_y =10self.init_state =54self.shortcut_state =64def toggle_shortcut(self):ifself.shortcut_state ==64:self.shortcut_state =2else:self.shortcut_state =64def get_outcome(self, state, action):if state ==99: reward =0 next_state =Nonereturn next_state, reward reward =0if action ==0: next_state = state +1if state ==98: reward =1elif state %10==9: next_state = stateelif state in [11, 21, 31, 41, 51, 61, 71,12, 72,73,14, 74,15, 25, 35, 45, 55, 65, 75]: reward =-1elif action ==1: next_state = state +10if state ==89: reward =1if state >=90: next_state = stateelif state in [2, 12, 22, 32, 42, 52, 62,3, 63,self.shortcut_state,5, 65,6, 16, 26, 36, 46, 56, 66]: reward =-1elif action ==2: next_state = state -1if state %10==0: # left border next_state = stateelif state in [17, 27, 37, 47, 57, 67, 77,16, 76,75,14, 74,13, 23, 33, 43, 53, 63, 73]: reward =-1elif action ==3: next_state = state -10if state <=9: next_state = stateelif state in [22, 32, 42, 52, 62, 72, 82,23, 83,84,25, 85,26, 36, 46, 56, 66, 76, 86]: reward =-1else:print("Accion debe ser entre 0 y 3.") next_state =None reward =Nonereturnint(next_state) if next_state isnotNoneelseNone, reward```
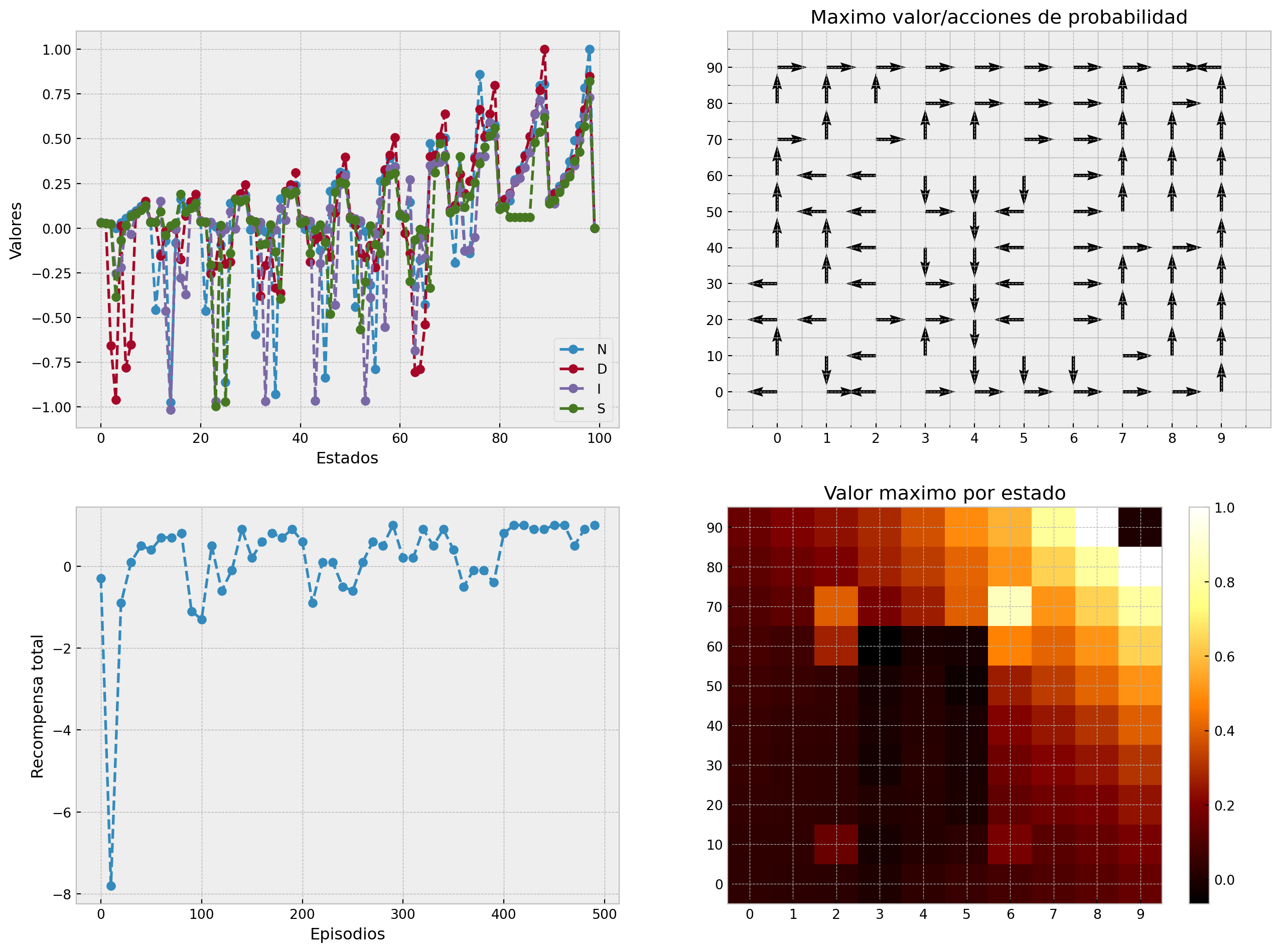
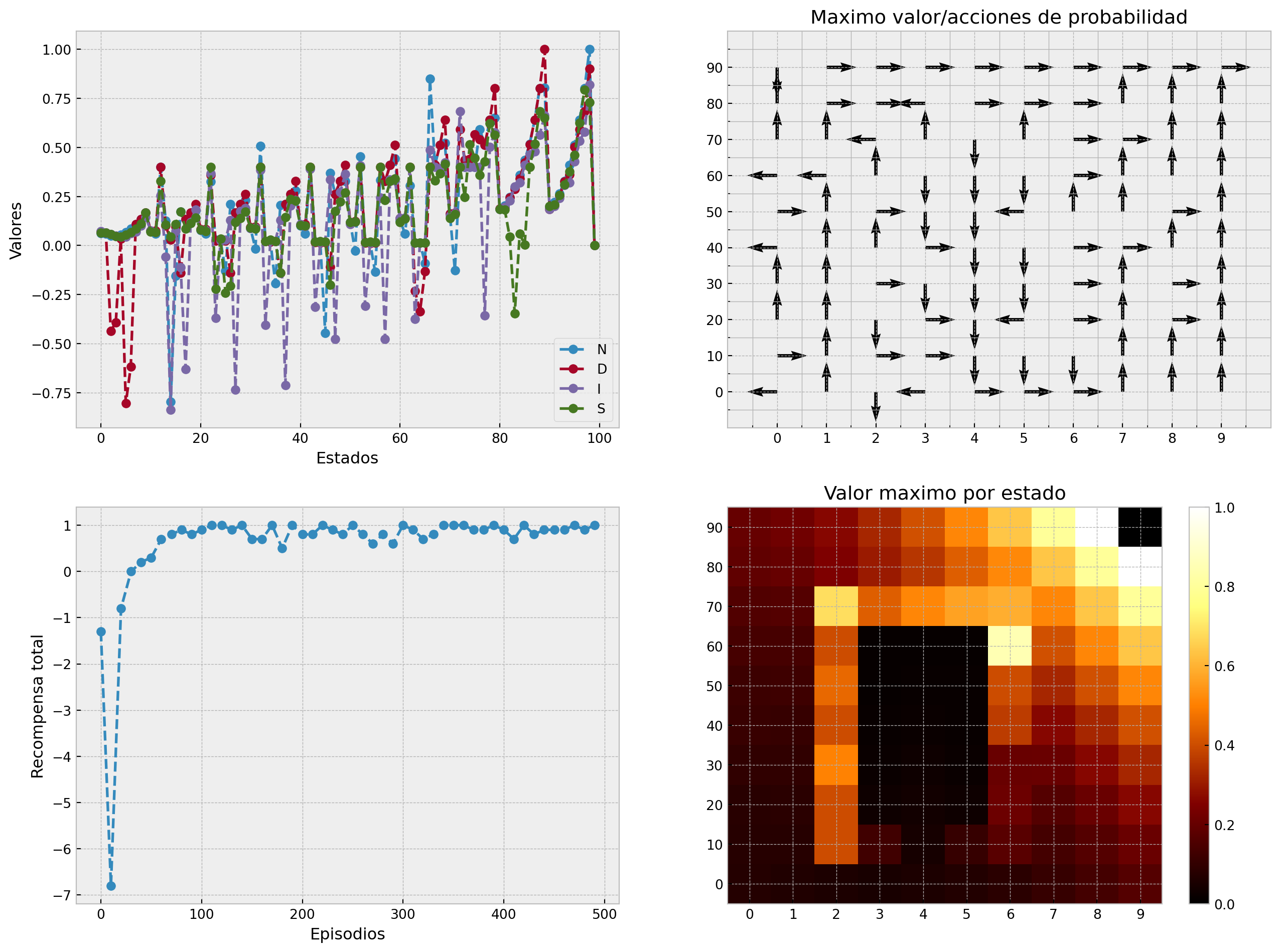
En las 4 gráficas vemos el comportamiento del algoritmo. En la esquina izquierda superior tenemos los valores Q para cada una de las acciones en cada estado. Podemos ver que dependiendo del estado actual ciertas acciones tendrán un valor mayor o menor. Como al estar abajo o la lado del objetivo esta acción tendra un valor mayor, que ir a la derecha o izquierda. En la esquina superior derecha tenemos el valor máximo de cada acción, es decir si tomaramos la acción greedy,se tomaría la dirección marcada. Podemos ver en cada estado cual sería la acción óptima aprendida por el algortimo. En la esquina inferior izquierda vemos el refuerzo obtenido a través del tiempo por el algoritmo. Y en la esquina inferior derecha vemos de acuerdo a una escala de colores el valor de cada estado en el ambiente. A continuación comparamos los resultados de cada algoritmo.