Modelo de la Teoría del Campo de Decisión Multialternativa
Autor/a
Pamela Cabañas, Lab 25
Video
Simulación
Simulación adpatada del trabajo de Roe, R. M., Busemeyer, J. R., & Townsend, J. T. (2001). Multialternative decision field theory: A dynamic connectionst model of decision making. Psychological review, 108(2), 370.
Proceso de decisión
Valencias.
Valencias: El valor de cada alternativa dentro del conjunto de opciones a través del tiempo.
La valencia para la opción i en el momento t representa la ventaja o desventaja que tiene la opción i al compararla con algún atributo de las demás opciones.
Así pues, dicho conjunto de valencias para todas las opciones forma un vector de valencia:
\[v_i(t)\]
Es decir, una elección entre las alternativas {A, B y C} , produce un vector de valencia tridimensional:
\[\\ V (t) = [v_a(t), v_b(t), v_c(t)]'\]
Dicho vector de valencias está determinado por:
Evaluación personal
Pesos de atención
Un proceso de comparación
1. Evaluación personal
Evaluación de cada opción en cada atributo.
Valor subjetivo de la opción i en el atributo j
\[m_{ij}\]
Por ejemplo, supongamos que queremos comprar un cereal. Tenemos tres opciones de cereales {A, B y C} y dos atributos que para nosotros son muy importantes al momento de decidir cuál comprar, los cuales son el precio y la calidad del producto.
Por lo que tendríamos el siguiene vector:
\[ M = [m_A, m_B, m_C]'. \]
Entonces, en el siguiente vector se representan las tres evaluaciones realizadas para los tres cereales respecto a su precio:
\[ M_P = [m_{AP}, m_{BP}, m_{CP}]. \]
Y el vector respecto a su calidad, sería:
\[ M_C = [m_{AC}, m_{BC}, m_{CC}]. \]
Es decir, si el Cereal A tiene una mayor calidad que el Cereal B, entonces a \(m_{AC}\) se le asigna un valor más alto en la escala que a \(m_{BC}\) por lo que tenemos que \(m_{AC} > m_{BC}\) y dicha concatenación entre los dos vectores forma una matriz de los valores 3x2. \[ M = [M_P| M_C].\]
Ahora pasemos a algo más divertido, representar en código los elementos que tenemos hasta ahora.
Haz Clic para ver el Código
```{python}#Cargamos las librerias necesarias:import numpy as np import pandas as pdimport random as randomimport matplotlib.pyplot as pltimport mathfrom collections import Counter#Primero creamos una matriz que represente el ejemplo de los cereales A, B y Ccereales = np.array([['', 'Precio', 'Calidad' ], ['Cereal_A', 2, 9], ['Cereal_B', 4, 6], ['Cereal_C', 6, 3], ])M = (pd.DataFrame(data=cereales[1:,1:], index=cereales[1:,0], columns=cereales[0,1:]))# cambiar a valores numéricosM.Precio = pd.to_numeric(M.Precio)M.Calidad = pd.to_numeric(M.Calidad)```
Ahora creamos la matriz 3x2 que repreenta el vector de la evaluación personal que mencionamos anteriormente. \[ M = [M_P| M_C].\]
Haz Clic para ver el Código
```{python}#llamamos a nuestra matriz M```
Precio
Calidad
Cereal_A
2
9
Cereal_B
4
6
Cereal_C
6
3
Graficamos la matriz de cereales.
Haz Clic para ver el Código
```{python}# Graficamos la matriz de cerealesfig, ax = plt.subplots()plt.scatter(M.Precio, M.Calidad, s=50, c='blue', alpha=0.5)for i inrange(M.shape[0]): plt.text(M.Precio[i]+0.2, M.Calidad[i], str(M.index[i]))ax.set_xlim(0, 10)ax.set_xticks(np.arange(0,10,1))ax.set_xlabel('Precio')ax.set_ylim(0, 10)ax.set_yticks(np.arange(0,10,1))ax.set_ylabel('Calidad')ax.set_title('Evaluación de cereales')#ax.grid(True)plt.show()```
2. Pesos de atención
Atención dada a cada atributo en un momento y que puede variar a lo largo del tiempo.
En donde la atención momentánea dada al atributo j está representada por un peso de atención \(W_{j}(t)\) en el tiempo t
En el caso de nuestro ejempo tenemos dos pesos de atención \(W_P(t)\) para el precio y \(W_C(t)\) para la calidad
Haz Clic para ver el Código
```{python}# Simluación de los pesos #Asumimos que la probabilidad de atender entre el Precio y la Calidad es de .5/.5 # Peso de Precio para 5 puntos en el tiempo W_Precio = np.random.randint(2, size=(5))# # Peso de Calidad para 5 puntos en el tiempo W_Calidad =abs(W_Precio -1)#Colocamos los datos en forma de matrices para los dos vectores pesos = np.array([W_Precio, W_Calidad]).T# Generar un Dataframe con la matrizW = (pd.DataFrame(data=pesos, columns = ['Precio', 'Calidad'] ))#Al llamar a la función, los datos serán diferentes cada vez que los corramos dado que utilizamos la función random (aleatorio)W```
Precio
Calidad
0
1
0
1
0
1
2
0
1
3
0
1
4
0
1
Dichos pesos de atención fluctúan a través del tiempo asumiendo un proceso estacionario y que esta atención cambia de una forma de todo o nada de un atributo en un momento dado \(W_C(t) = 1, W_P(t) = 0\) a otro atributo en otro momento \(W_C(t + 1) = 0, W_P(t + 1) = 1\) con probabilidades fijas.
En donde la probabilidad de atender a la dimensión de Precio se denota como \(w_P\) y la probabilidad de atender a la dimensión de Calidad es de \(w_C\).
Los pesos de atención para todos los atributos genera un vector de peso $ W(t)$
En el caso de nuestro ejemplo en donde compramos un cereal con solo dos tributos (Precio y Calidad) el vector de peso es bidimensional:
\(W(t) = [W_P(t)W_C(t)]'\).
Simluación de los pesos. Asumimos que la probabilidad de atender entre el Precio y la Calidad es de .5/.5.
Ahora veamos cuáles son los pesos de los atributos para cada Cereal en el tiempo 2
Haz Clic para ver el Código
```{python}#Fijamos el tiempo que queremos ver t =2#Hacemos una matriz con los valores de los pesos W_t = np.ones((3,2), dtype =int) * np.array([W.iloc[t]])#Generamos un DataFrame para poder v¡isualizarlos mejorW_t = (pd.DataFrame(data=W_t, columns = ['Precio', 'Calidad'], index = ['Cereal_A', 'Cereal_B', 'Cereal_C'] ))# Lllamos a la matrizW_t```
Precio
Calidad
Cereal_A
0
1
Cereal_B
0
1
Cereal_C
0
1
El producto de la matriz de pesos y valores \(MW(t)\) determina el valor del peso de atención en cada momento dado.
En nuestro ejemplo, al elegir entre los tres Cereales, la ith fila sería:
\(M W(t) = W_P(t)m_{iP} + W_C(t)m_{iC}\)
Los valores de los pesos son estocásticos dadas las fluctuaciones de los pesos de atención \(W_P(t)\) y \(W_C(t)\).
Representemos la matriz de pesos y valores. Continuamos con el tiempo 2
Graficamos los pesos para los Cereales en el tiempo 2
Haz Clic para ver el Código
```{python}fig, ax = plt.subplots()plt.scatter(M_Wt.Precio, M_Wt.Calidad, s=50, c='blue', alpha=0.5)for i inrange(M_Wt.shape[0]): plt.text(M_Wt.Precio[i]+0.2, M_Wt.Calidad[i], str(M_Wt.index[i]))ax.set_xlim(0, 10)ax.set_xticks(np.arange(0,10,1))ax.set_xlabel('Precio')ax.set_ylim(0, 10)ax.set_yticks(np.arange(0,10,1))ax.set_ylabel('Calidad')ax.set_title('Evaluación de cereales')#ax.grid(True)plt.show()```
Proceso de Comparación
Contrasta las las evaluaciones de los pesos de cada ocpión.
Durante este proceso se determina la ventaja o desventaja de cada opción en el atributo que se está considerado en ese momento. Así la valencia de cada opción se obtiene contrastando los valores de los pesos de una alternativa con el promedio de todas las demás.
En nuestro ejemplo las tres alternativas de Cereales {A, B y C} la valencia de la opción A se calcula:
Hagamos el cálculo con los valores generados anteriormente en los pesos de decisión para el tiempo 2.
Haz Clic para ver el Código
```{python}t =2Valencia_A_t = W.Precio[t]*M.Precio['Cereal_A'] + W.Calidad[t]*M.Calidad['Cereal_A'] \- (W.Precio[t]*M.Precio['Cereal_B'] + W.Calidad[t]*M.Calidad['Cereal_B'] + W.Precio[t]*M.Precio['Cereal_C'] + W.Calidad[t]*M.Calidad['Cereal_C'])/2print('Valencias para el Cereal A en el tiempo {0} = {1}'.format(t, Valencia_A_t))```
Valencias para el Cereal A en el tiempo 2 = 4.5
Valencias para el Cereal A en el tiempo 2 = 4.5
De igual forma este proceso de comparación se puede representar con una matriz de contraste
```{python}t =2# V(t) = CMW(t)V_t = C.dot(M).dot(W.iloc[t])print('Valencia del Cereal A en t={0} es {1}\nValencia del Cereal B en t={0} es {2}\nValencia del Cereal C es t={0} es {3}\n'.format(t, V_t[0], V_t[1], V_t[2]))```
Valencia del Cereal A en t=2 es 4.5
Valencia del Cereal B en t=2 es 0.0
Valencia del Cereal C es t=2 es -4.5
Inhibición Lateral
Esta inhibición depende de la distancia; es decir, cuanto más cerca están dos opciones en el espacio de elección, mayor inhibición lateral ejercen entre sí.
Haz Clic para ver el Código
```{python}CerealA_CerealB = math.hypot(M.Precio[0] - M.Precio[1], M.Calidad[0] - M.Calidad[1])CerealA_CerealC = math.hypot(M.Precio[0] - M.Precio[2], M.Calidad[0] - M.Calidad[2])CerealB_CerealC = math.hypot(M.Precio[1] - M.Precio[2], M.Calidad[1] - M.Calidad[2])print('Distancia entre el Cereal A y el Cereal B = {0:.2f}'.format(CerealA_CerealB))print('Distancia entre el Cereal A y el Cereal C = {0:.2f}'.format(CerealA_CerealC))print('Distancia entre el Cereal B y el Cereal C = {0:.2f}'.format(CerealB_CerealC))```
Distancia entre el Cereal A y el Cereal B = 3.61
Distancia entre el Cereal A y el Cereal C = 7.21
Distancia entre el Cereal B y el Cereal C = 3.61
Predicción del efecto de similitud.
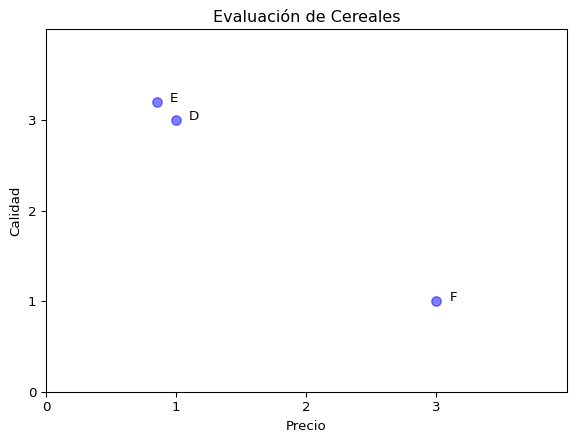
Consideremos el ejemplo de la elección entre tres Cereales {D, E y F} y seguimos el proceso que describimos anteriormente.
Generamos nuestra matriz con los nuevos valores (obtenidos del artículo original).
Precio Calidad
0 1.00 3.0
1 0.85 3.2
2 3.00 1.0
Precio Calidad
Cereales
D 1.00 3.0
E 0.85 3.2
F 3.00 1.0
Graficamos las alternativas.
Haz Clic para ver el Código
```{python}fig, ax = plt.subplots()plt.scatter(M_e.Precio, M_e.Calidad, s=50, c='blue', alpha=0.5)for i inrange(len(M_e.index)): plt.text(M_e.Precio[i]+0.1, M_e.Calidad[i], str(M_e.index[i]))ax.set_xlim(0, 4)ax.set_xticks(np.arange(0,4,1))ax.set_xlabel('Precio')ax.set_ylim(0, 4)ax.set_yticks(np.arange(0,4,1))ax.set_ylabel('Calidad')ax.set_title('Evaluación de Cereales')plt.show()```
En la figura podemos observar el efecto de Atracción.
Pesos de atención.
Consideramos para los pesos de atención del Precio \(w_P\) y para Calidad \(w_C\).
Haz Clic para ver el Código
```{python}w_c =0.45w_p =0.43# Vector de pesosw_vector = np.array([w_c, w_p, (1-w_c-w_p)]) #dentro de la matriz inlcuimos también los pesos generados por ruido en el set de opcionesw_vector```
array([0.45, 0.43, 0.12])
Calculamos los pesos de decisión para cualquier momento en el tiempo.
Realizamos una matriz y seleccionamos una fila de la matriz partir de los pesos de atención.
Haz Clic para ver el Código
```{python}mat_iden = np.eye(len(alternativas))i = np.random.choice([0,1,2], 1, p=w_vector) # p es la probabilidad del muestreow_vec_ch = mat_iden[i]w_vec_ch```
array([[0., 0., 1.]])
Matriz de retroalimentación.
Contiene las autoconexiones e interconexiones entre las alternativas de elección
\(S_{ii}\).
\(S_{ii} = 0\) (no se tiene memoria del estado anterior).
\(S_{ii} = 1\) (memoria perfecta del estado anterior).
Si las interconexiones son todas cero, entonces las alternativas no compiten en absoluto y crecen o decaen de forma independiente y en paralelo.
Si las interconexiones son negativas, las alternativas fuertes suprimen a las alternativas débiles.
Las fortalezas de las interconexiones están determinadas por el concepto de inhibición lateral, en donde la fuerza de la interconexión lateral entre un par de opciones es una función decreciente de la distancia entre estas dos opciones en el espacio de atributos múltiples.
Ahora generamos una función que nos permita realziar múltiples simulaciones.
Haz Clic para ver el Código
```{python}def simul_multiple(S, M, w_vector, time_steps, noise, sim_num=1):""" S: Matriz de retroalimentación C: Matriz de contraste w_vec: Vector de los pesos del atributo time_steps: Número de puntos en el tiempo a simular noise: Escala del valor del ruido sim_num: Número de simulaciones """ length = time_steps noise_scale = noise alternativas = M.shape[0] mat_iden = np.eye(alternativas) m_contr =-1/(alternativas -1) C = np.full((alternativas, alternativas), m_contr) np.fill_diagonal(C, 1) P = np.zeros((alternativas,length,sim_num))for i inrange(0,sim_num):for t inrange(1,length):# Se asigna aleatoriamente la atención, de acuerdo a los pesos de cada atributo j = np.random.choice([0,1,2], 1, p=w_vector) w_vec_ch = mat_iden[j]# las dos primeras columnas contienen los valores de atención, sin considerar el ruido P[:,t,i] = S.dot(P[:,t-1,i]) + (C.dot(M).dot(w_vec_ch[0,0:2]) \+ np.random.normal(0,noise_scale) * w_vec_ch[0,2]) # se añade el ruidoreturn P```
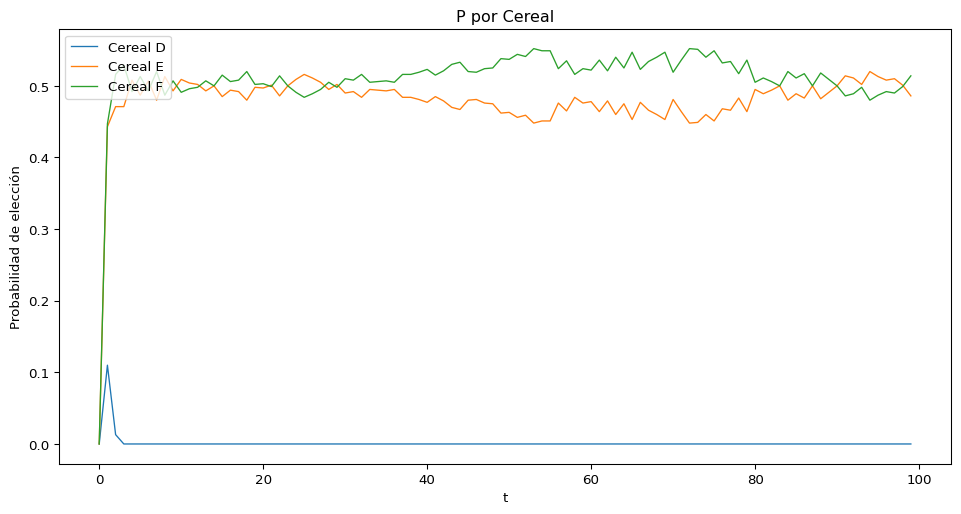
Analizamos la proporción de cada opción que es elegida en cualquier momento dado.
Ahora calculamos la probabilidad de elección en cada momento de acuerdo a la simulación generada y generamos la gráfica donde podemos ver mejor cómo se presentan las probabilidades de elección en cada set de opciones.
Haz Clic para ver el Código
```{python}def probabilidad_decision(sims, M, time_steps): alternativas = M.shape[0] length = time_steps sim_num = sims.shape[2] fila_decision = np.zeros((alternativas, length))# se cuenta el número de veces que cada opción fue elegida en un momento dadofor i inrange(1,length): count = np.array(sims[:,i,:]).argmax(0) frequency = Counter(count) fila_decision[0,i] = frequency[0]/sim_num # D fila_decision[1,i] = frequency[1]/sim_num # E fila_decision[2,i] = frequency[2]/sim_num # Freturn fila_decisiondecisiones = probabilidad_decision(x, M_e, 100)fig = plt.figure(figsize=(12,6))ax = fig.add_subplot(111)ax.plot(decisiones[0,:], linewidth=1.0) # Aax.plot(decisiones[1,:], linewidth=1.0) # Sax.plot(decisiones[2,:], linewidth=1.0) # Bax.legend(['Cereal D', 'Cereal E', 'Cereal F'], loc='upper left')ax.set_xlabel('t')ax.set_ylabel('Probabilidad de elección')ax.set_title('P por Cereal') plt.show()```
De acuerdo a la gráfica, podemos ver que el modelo MDFT simula el efecto de similitud.