El dilema de exploración-explotación es un dilema que existe en muchas facetas de nuestra vida.Tomemos un ejemplo comunmente usado respecto a las posibles parejas que podríamos tener en nuestra vida y cuando sería el momento apropiado para “sentar cabeza”. Si tienes una pareja por mucho tiempo ya sabes el tipo de interacción que tienes, o la cantidad de momentos agradables vs problemas, que tienes con esta. Sin embargo, si cambias constantemente de pareja realmente no conoces del todo esta nueva persona, no sabes bien el tipo de interacción y lo bien o mal que te puedas llevar con estas parejas desconocidas. Sin embargo, el dilema consiste en como saber que la pareja con la que estas es la mejor opción y como saber cuando es tiempo de dejar de buscar otras parejas y elegir alguna. En esto consiste el dilema. Trasladandolo al campo de inteligencia artifical, si has aprendido toda la información acerca del ambiente, si sabemos absolutamente todas las parejas disponibles y el valor de cada una, la decisión es sencilla,solo tomar la de mayor valor. El problema existe cuando se tiene información incompleta, y necesitamos recolectar suficiente información para poder maximizar la recompensa y minimizar el riesgo. Una forma de cuantificar y hacer experimentación en el campo se refiere a los “bandidos”, que basicamente son máquinas al ser usadas tienen una cierta probabilidad para dar una cierta recompensa, el paradigma consiste en que el tiempo es limitado y solo puedes usar 1 en cada momento. La pregunta es: ¿Cual es la mejor estrategia para maximizar las recompensas?
Si tenemos a un agente que debe seleccionar que maquina usar. Lo primero que el agente debe de decidir es cual escoger.Aunque podriamos solo elegir aleatoriamente, queremos tener alguna creencia que justifique o describa cada decisión.Esto en la literatura se ejemplifica con el uso de una politica determinada por \(\color{blue}{\pi}\). También se necesita una función de valor por cada acción, al valor se le conoce como valor \(\color{green}{Q}\) . El valor \(\color{green}{Q}\) por tomar la acción \(\color{blue}{a \in A}\) en un tiempo determinado como \(t\) que no dará el valor de la recompensa en este tiempo \(r_t\) dada la acción elegida \(\color{blue}{a}\) . La fórmula es la siguiente:
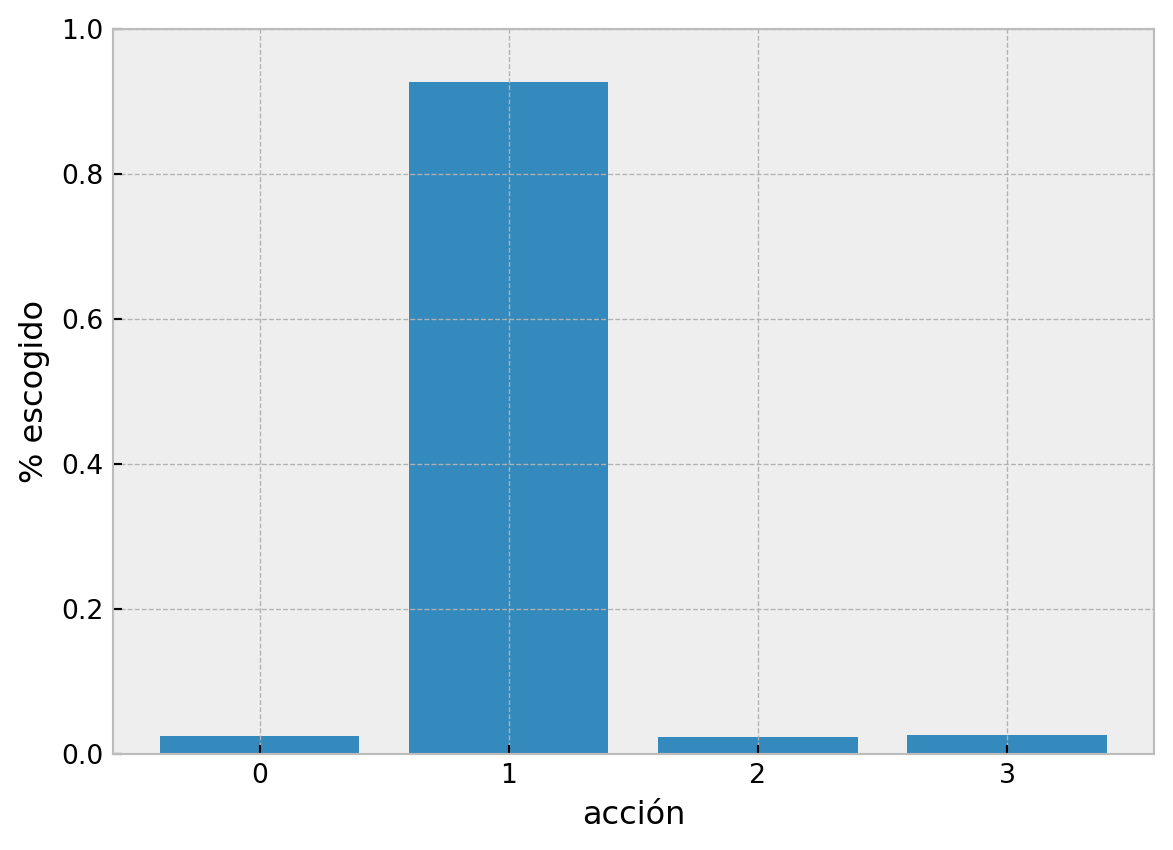
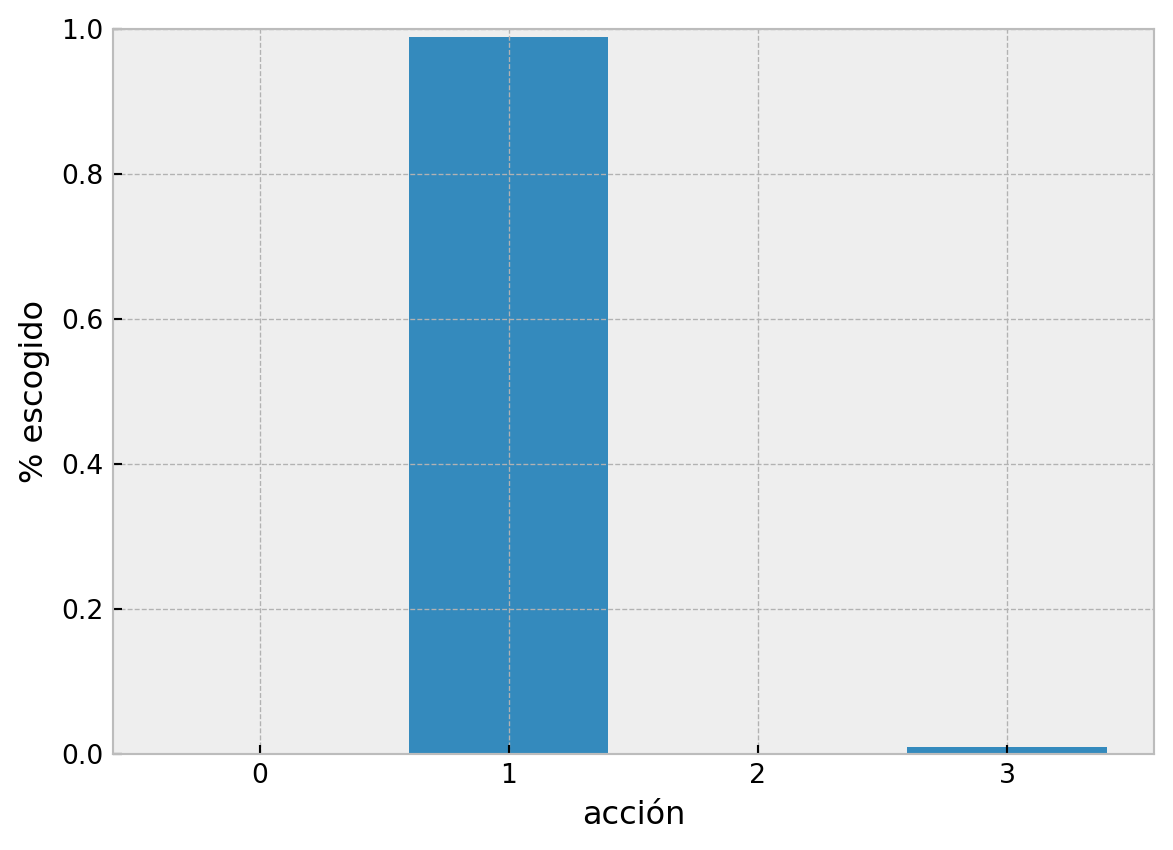
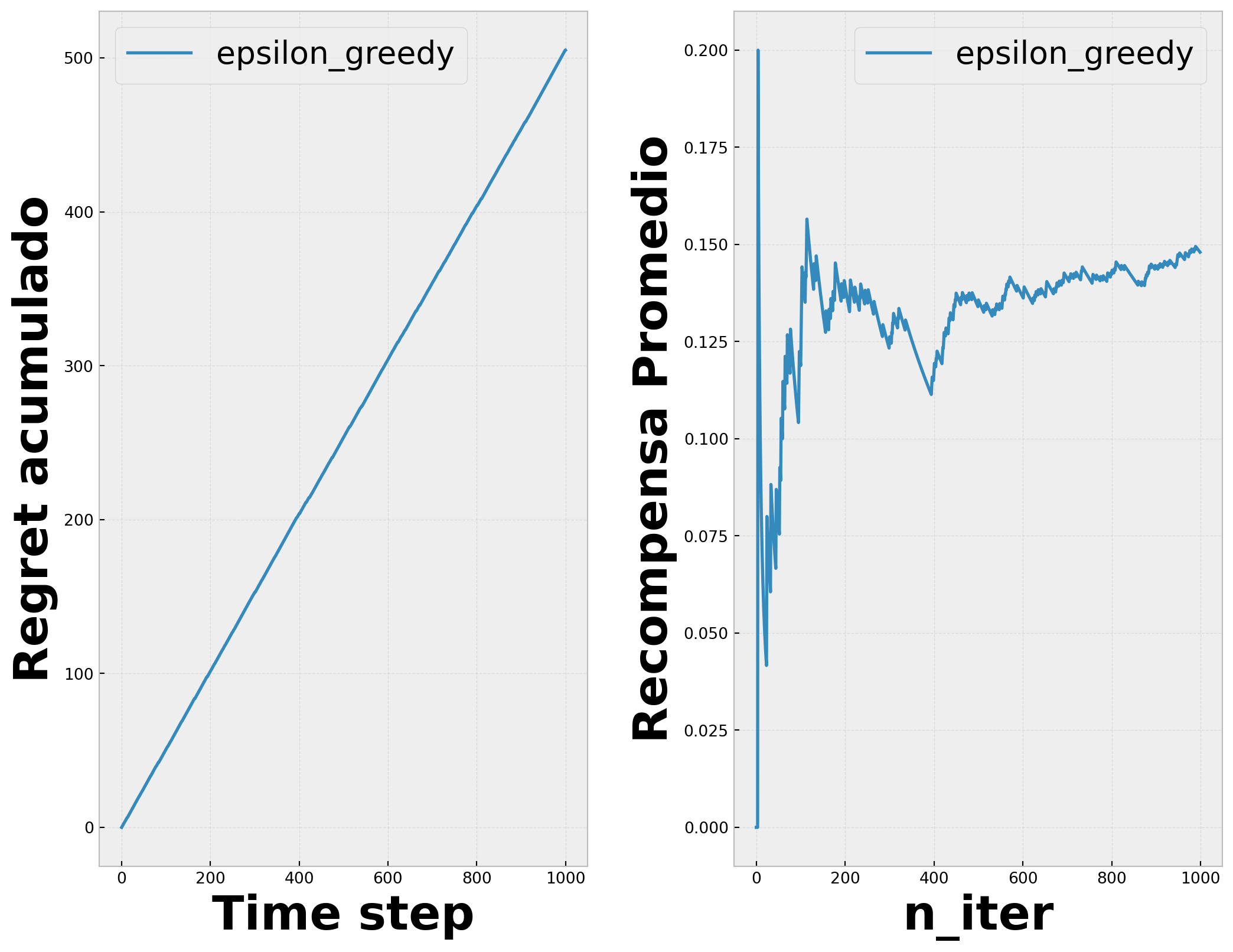
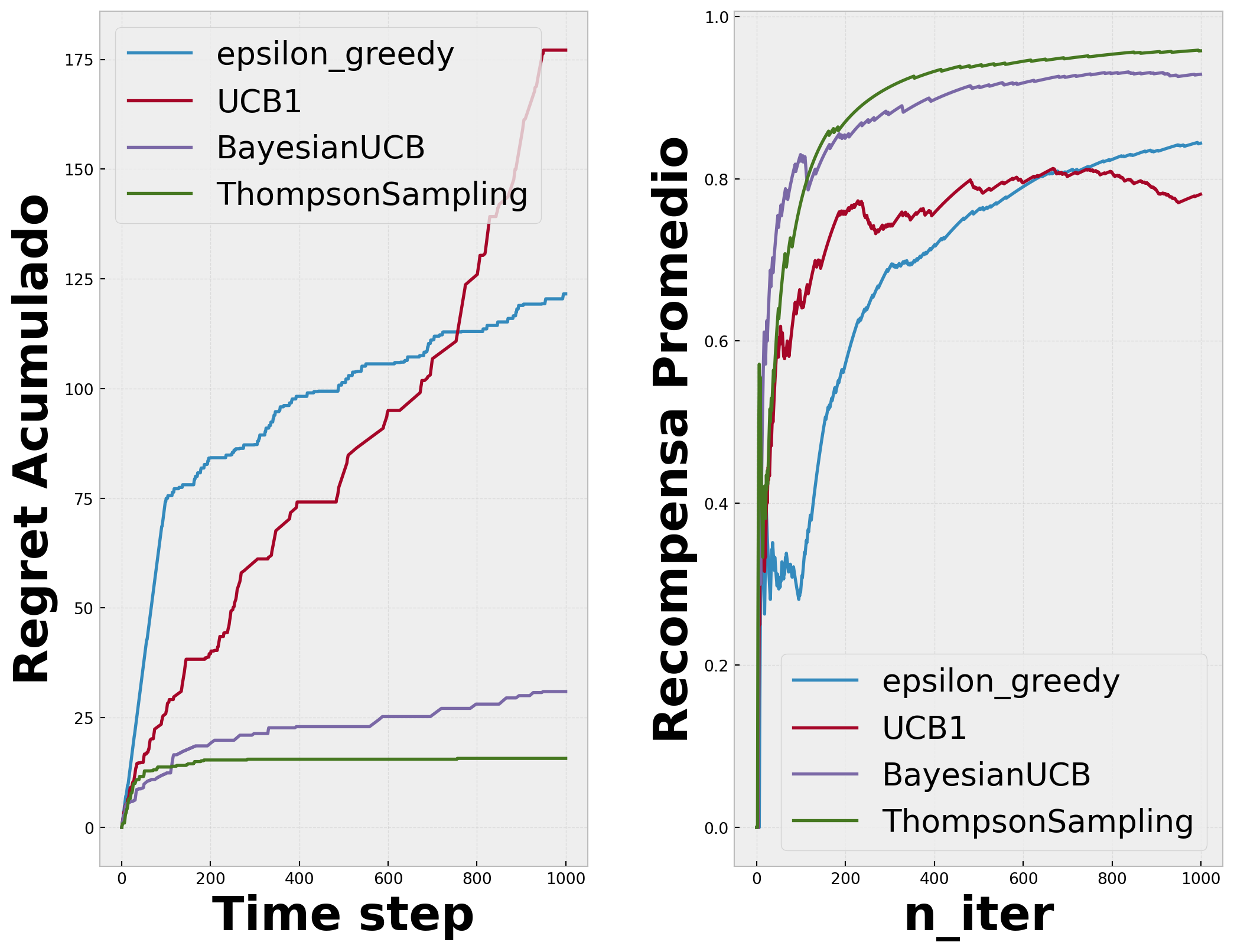
Pero retomando lo aprendido acerca del dilema de exploración-exploración, si siempre tomamos la opción de mayor valor no sabemos bien cual es el valor del resto de las opciones o ¿de que nos estamos perdiendo? La solución más común a este problema es agregar un poco de aletoriedad al modelo. Determinar una probabilidad en la que se toma una acción diferente a la que tiene el valor máximo. Normalmente a esta estrategia se le llama “epsilon greedy”, que indica que 1 - \(\epsilon\) para \(\epsilon \in [0,1]\) seleccionamos la opción con mayor valor o “greedy”, en caso contrario con una probabilidad pequeña \(\epsilon\) elegimos una acción aleatoriamente (incluyendo la opción con mayor valor)
Otro concepto importante es REGRET , o “arrepentimiento”, básicamente es que tanto nos arrepentimos de seleccionar la acción elegida y no la opción optima en ese momento. Matematicamente la identificamos como:
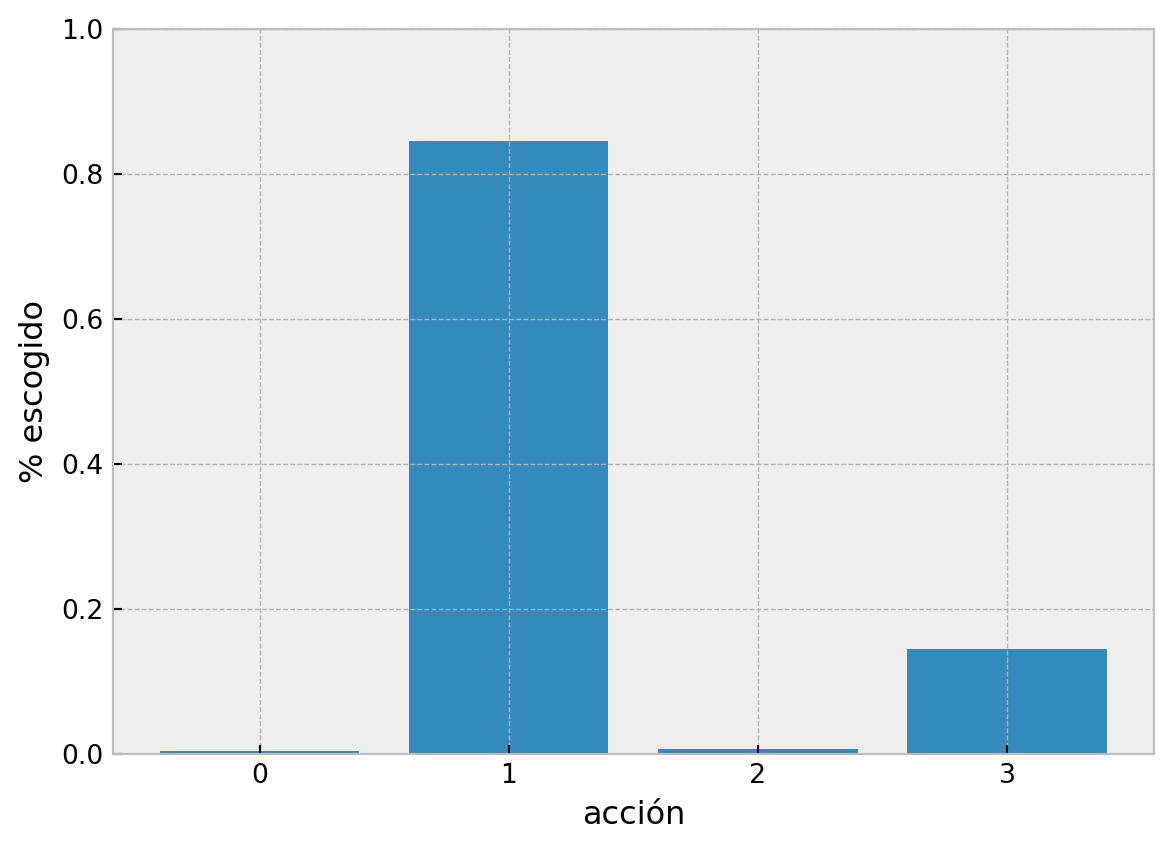
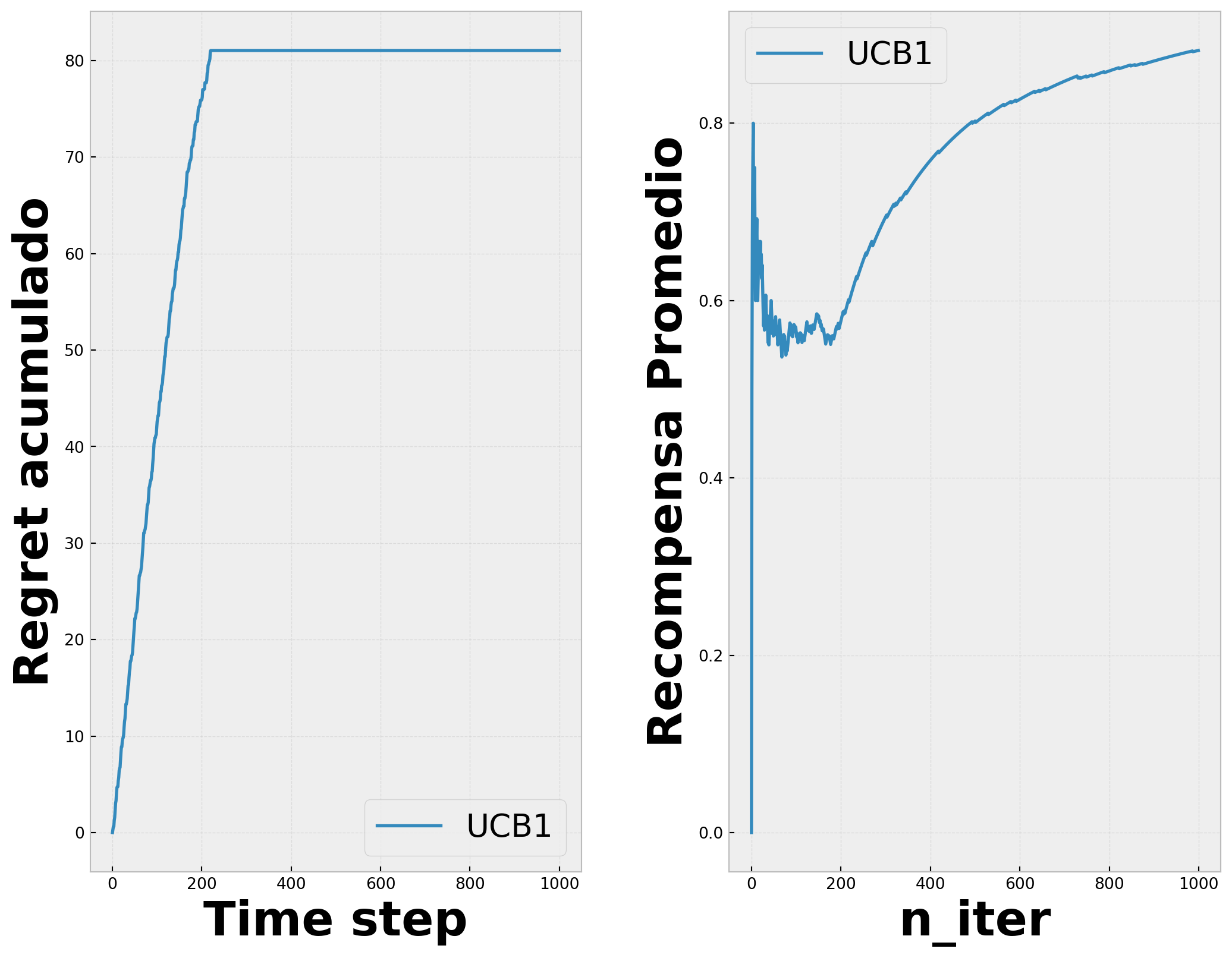
Este algortimo nos permite, a diferencia de e-greedy,no tener una exploración por medio una acción arbitraria escogida con una cierta probabilidad constante, este algoritmo cambia su balanceo de exploración-explotación cuando va recolectando más información del ambiente. Cambia de ser principalmente exploratorio a explotar mientras más información se tenga. El algoritmo esta represantado por:
\(c\) : Es un valor de confianza que controla la exploración
\(Q_t(a)\): el valor estimado de la acción en el tiempo
\(N_t(a)\): El numero de veces que esa acción ha sido seleccionada antes del tiempo \((t)\)
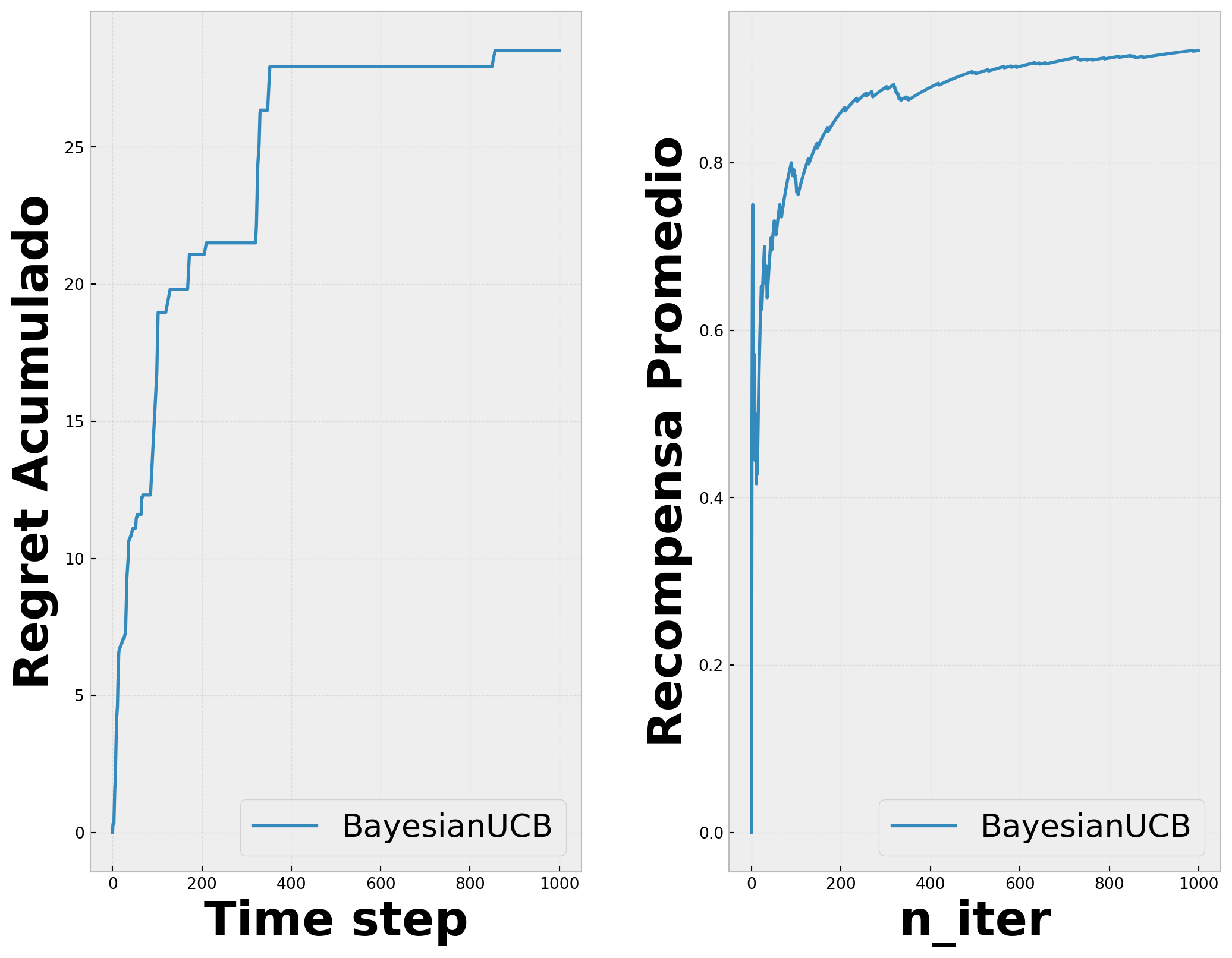
En UCB normal, no se asume ningún prior bayesiano en la dsitribución de recompensa y se usa la inequidad de Hoeffding para generalizar estimaciones. Si sabemos que forma tiene esta distribución, o podemos hacer una buena estimación, podremos hacer que los “bounds” también sean una mejor estimación.
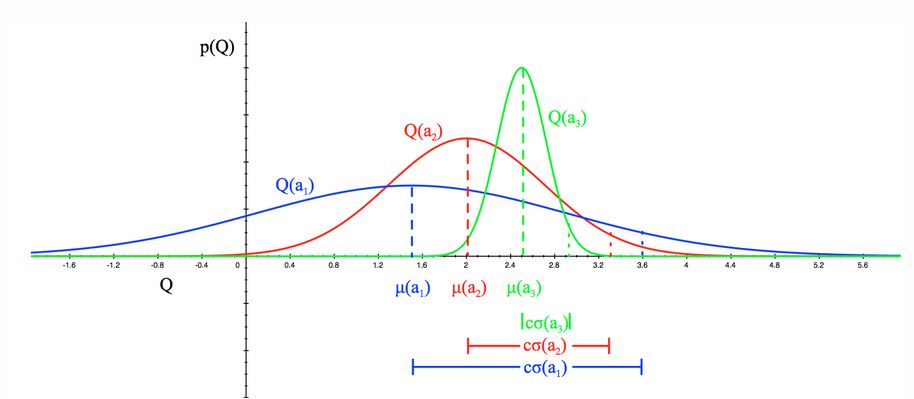
Uno de los acercamientos más novedosos para resolver el problema, consiste en que a cada paso se selecciona una acción de acuerdo a una probabilidad “optima” \(\pi(a \vert h_t)\):
Siendo \(\pi(a \vert h_t)\) la probabilidad de tomar una acción dada la historia \(h_t\)
Para este bandido en particular se asume un prior \(Beta(\sigma,\beta)\), con \(\sigma\) y \(\beta\) de acuerdo a las veces que hemos tenido exito o fallado.
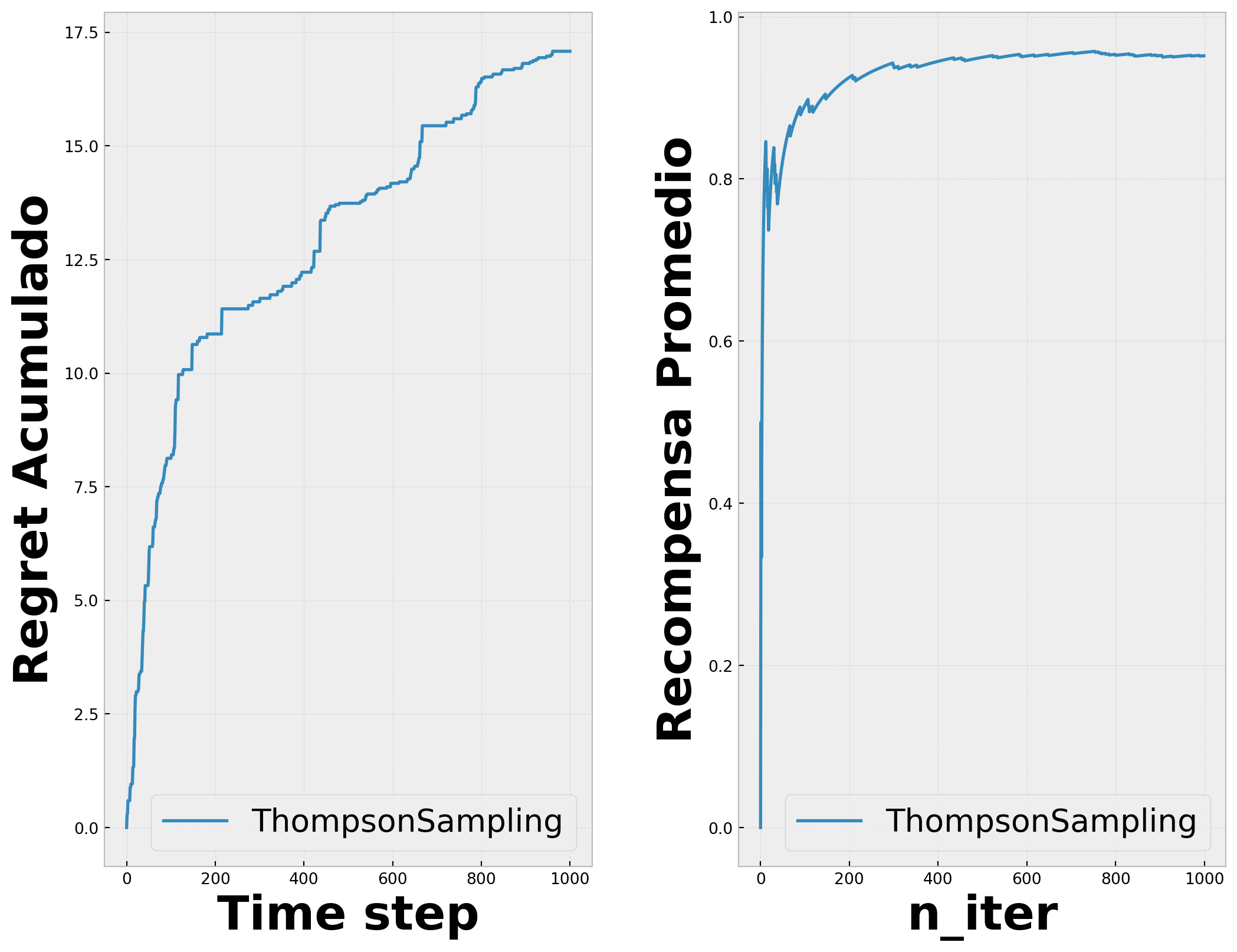
Primero se inicializan las variables de acuerdo con el nivel de confianza acerca de obtener la recompensa, y en cada tiempo \(t\) se samplea una recompensa esperada \(Q(a)\) de la distribución prior para cada acción, seleccionando la mejor. Después de observar la verdadera recompensa, se puede actualizar la distribución \(Beta\), que es basicamente inferencia Bayesiana, para poder computar la posterior con el prior y el likelihood. \(a^{TS}t = \arg\max{a \in \mathcal{A}} \tilde{Q}(a)\)