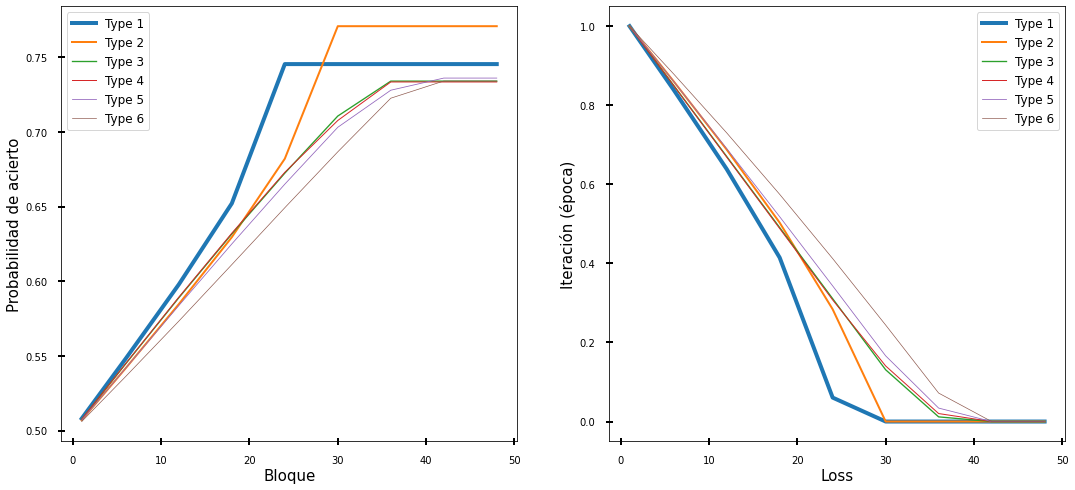
Haz Clic para ver el Código
```{python}
import torch
import torch.nn as nn
import torch.optim as optim
from scipy.stats import sem
from itertools import permutations
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import ipywidgets as widgets
%matplotlib inline
# Indica el tipo de Función de pérdida a ser usada.
def get_label_coding(loss_type):
# Set coding for class A and class B
POSITIVE = 1.
if loss_type == 'hinge':
NEGATIVE = -1.
elif loss_type == 'll':
NEGATIVE = 0.
else:
assert False
return POSITIVE,NEGATIVE
# Gestiona los datos
def load_shj(loss_type, lbs, exe):
# Loads SHJ data from text files
#
# Input
# loss_type : either ll or hinge loss
#
# Output
# X : [ne x dim tensor] stimuli as rows
# y_list : list of [ne tensor] labels, with a list element for each shj type
stimuli = exe.to_numpy()
labels = lbs.to_numpy()
stimuli = stimuli.astype(float)
ntype = labels.shape[0]
POSITIVE,NEGATIVE = get_label_coding(loss_type)
labels_float = np.zeros(labels.shape,dtype=float)
labels_float[labels == 'A'] = POSITIVE
labels_float[labels == 'B'] = NEGATIVE
X = torch.tensor(stimuli).float()
y_list = []
for mytype in range(ntype):
y = labels_float[mytype,:].flatten()
y = torch.tensor(y).float()
y_list.append(y)
return X,y_list
# Gestiona los datos para hacerlos válidos para el modelo.
def load_shj_abstract(loss_type, exe, lbs, perm=[0,1,2]):
# Loads SHJ data in abstract form
#
# Input
# loss_type : either ll or hinge loss
# perm : permutation of abstract feature indices
#
# Output
# X : [ne x dim tensor] stimuli as rows
# y_list : list of [ne tensor] labels, with a list element for each shj type
# load image and abstract data
X,y_list = load_shj(loss_type, lbs, exe)
X_abstract = X.data.numpy().astype(int)
# Apply permutation
X_perm = X_abstract.copy()
X_perm = X_perm[:,perm] # permuted features
perm_idx = []
for x in X_perm:
idx = np.where((X_abstract == x).all(axis=1))[0] # get item mapping from original order to perm order
perm_idx.append(idx[0])
perm_idx = np.array(perm_idx)
X = X[perm_idx,:] # permute items from original order to permuted order
return X,y_list
class ALCOVE(nn.Module):
def __init__(self, exemplars, c=10, phi=1):
# Input
# exemplars: [ne x dim] rows are exemplars provided to model
super(ALCOVE, self).__init__()
self.ne = exemplars.size(0) # number of exemplars
self.dim = exemplars.size(1) # stimulus dimension
self.exemplars = exemplars # ne x dim
# set attention weights to be uniform
self.attn = torch.nn.Parameter(torch.ones((self.dim,1))/float(self.dim))
# set association weights to zero
self.w = torch.nn.Linear(self.ne,1,bias=False)
self.w.weight = torch.nn.Parameter(torch.zeros((1,self.ne)))
self.c = c # sharpness parameter (Kruschke uses 6.5 in SHJ simulations)
self.phi = phi # temperature when making decisions; not included in loss (Kruschke uses 2.0)
def forward(self,x):
# Input
# x: [dim tensor] a single stimulus
#
# Output
# output : [tensor scalar] unnormalized log-score (before sigmoid)
# prob : [tensor scalar] sigmoid output
x = x.view(-1,1) # dim x 1
x_expand = x.expand((-1,self.ne)) # dim x ne
x_expand = torch.t(x_expand) # ne x dim
attn_expand = self.attn.expand((-1,self.ne)) # dim x ne
attn_expand = torch.t(attn_expand) # ne x dim
# memory/hidden layer is computes the similarity of stimulus x to each exemplar
hidden = attn_expand * torch.abs(self.exemplars-x_expand) # ne x dim
hidden = torch.sum(hidden,dim=1) # ne
hidden = torch.exp(-self.c * hidden) # ne
hidden = hidden.view((1,-1)) # 1 x ne
# compute the output response
output = self.w(hidden).view(-1) # tensor scalar
prob = torch.sigmoid(self.phi*output) # tensor scalar
return output,prob
class MLP(nn.Module):
def __init__(self, nhid=8, phi=2.0):
# Input
# exemplars: [ne x dim] rows are exemplars provided to model
super(MLP, self).__init__()
self.ne = exemplars.size(0) # number of exemplars
self.dim = exemplars.size(1) # stimulus dimension
self.nhid = nhid
self.hid = torch.nn.Linear(self.dim,self.nhid)
self.out = torch.nn.Linear(self.nhid,1)
self.phi = phi
def forward(self,x):
# Input
# x: [dim tensor] a single stimulus
#
# Output
# output : [tensor scalar] unnormalized log-score (before sigmoid)
# prob : [tensor scalar] sigmoid output
x = x.view(1,-1) # dim x 1
x = self.hid(x)
x = torch.tanh(x)
output = self.out(x)
prob = torch.sigmoid(self.phi*output) # tensor scalar
return output,prob
def update_batch(net,exemplars,targets,loss,optimizer, model_type = False):
# Update the weights using batch SGD for the entire set of exemplars
#
# Input
# exemplars: [ne x dim tensor] all stimuli/exempalrs in experiment
# targets: [ne tensor] classification targets (1/0 or 1/-1, depending on loss)
# loss: function handle
# optimizer : SGD optimizer
net.zero_grad()
net.train()
n_exemplars = exemplars.size(0)
out = torch.zeros(n_exemplars)
for j in range(n_exemplars):
out[j],_ = net.forward(exemplars[j])
myloss = loss(out, targets)
myloss.backward()
optimizer.step()
if model_type == 'alcove':
net.attn.data = torch.clamp(net.attn.data, min=0.) # ensure attention is non-negative
else:
assert ValueError
return myloss.cpu().item()
def evaluate(net,exemplars,targets, loss_type):
# Compute probability of getting each answer/exemplar right using sigmoid
#
# Input
# exemplars: [ne x dim tensor] all stimuli/exempalrs in experiment
# targets: [ne tensor] classification targets (1/0 or 1/-1, depending on loss)
#
# Output
# mean probability of correct response
# mean accuracy when picking most likely response
POSITIVE,NEGATIVE = get_label_coding(loss_type)
net.eval()
n_exemplars = exemplars.size(0)
v_acc = np.zeros(n_exemplars)
v_prob = np.zeros(n_exemplars)
for j in range(n_exemplars):
out,prob = net.forward(exemplars[j])
out = out.item() # logit
prob = prob.item() # prob of decision
if targets[j].item()== POSITIVE:
v_prob[j] = prob
v_acc[j] = out >= 0
elif targets[j].item()== NEGATIVE:
v_prob[j] = 1-prob
v_acc[j] = out < 0
return np.mean(v_prob), 100.*np.mean(v_acc)
def HingeLoss(output, target):
# Reinterpretation of Kruschke's humble teacher
# loss = max(0,1-output * target)
#
# Input
# output : 1D tensor (raw prediction signal)
# target : 1D tensor (must be -1. and 1. labels)
hinge_loss = 1.-torch.mul(output, target)
hinge_loss[hinge_loss < 0] = 0.
return torch.sum(hinge_loss)
def train(exemplars,labels, lr_attn, lr_association,model_type,num_epochs,loss_type,track_inc=5,verbose_params=False, c = 10, phi = 1):
# Train model on a SHJ problem
#
# Input
# exemplars : [n_exemplars x dim tensor] rows are exemplars
# labels : [n_exemplars tensor] category labels
# num_epochs : number of passes through exemplar set
# loss_type : either 'll' or 'hinge'
# track_inc : track loss/output at these intervals
# verbose_params : print parameters when you are done
#
# Output
# trackers for epoch index, probability of right response, accuracy, and loss
# each is a list with the same length
n_exemplars = exemplars.size(0)
if model_type == 'mlp':
net = MLP()
elif model_type == 'alcove':
net = ALCOVE(exemplars, c, phi)
else:
assert False
if loss_type == 'll':
loss = torch.nn.BCEWithLogitsLoss(reduction='sum')
elif loss_type == 'hinge':
loss = HingeLoss
else:
assert False # undefined loss
optimizer = optim.SGD(net.parameters(), lr=lr_association)
if model_type == 'alcove':
optimizer = optim.SGD([ {'params': net.w.parameters()}, {'params' : [net.attn], 'lr':lr_attn}], lr=lr_association)
v_epoch = []
v_loss = []
v_acc = []
v_prob = []
for epoch in range(1,num_epochs+1):
loss_epoch = update_batch(net,exemplars,labels,loss,optimizer)
if epoch == 1 or epoch % track_inc == 0:
test_prob,test_acc = evaluate(net,exemplars,labels, loss_type)
v_epoch.append(epoch)
v_loss.append(loss_epoch / float(n_exemplars))
v_acc.append(test_acc)
v_prob.append(test_prob)
return v_epoch,v_prob,v_acc,v_loss
```