Uno de los principales regularidades encontradas en psicología es la Ley de Igualación (Matching Law) y ha sido replicada a tal grado que muchos autores han tomado este fenómeno como un axioma del comportamiento humano. En general la Ley de Igualación establece que:
Donde, \(\ P_L\) y \(P_L\) representan la tasa de respuesta en la opción izquierda y derecha correspondientemente; \(\ T_L\) y \(T_R\) representan el tiempo relativo en cada opción. La igualdad modela el hecho de que los organismos igualan la proporción de tiempo o “esfuerzo” en cada opción dependiendo de la proporción del refuerzo que otorga cada opción.
Maximización Local (Melioration) vs Maximización Global
La gran evidencia empírica de esta igualdad al sostenerse en muchas replicaciones y en diferentes especies llevo a la búsqueda de explicaciones que dieran cuenta de su aparición. Desde un punto de vista centrado en sistemas dinámicos la ley de igualación puede entenderse como un punto de equilibrio del sistema, en su búsqueda de obtener la mayor cantidad de reforzamiento dado el costo de actuar. Dos posibles mecanismos se han sugerido para lograr tal equilibrio.
Maximización Global.
Este mecanismo se basa en la idea de mazimizar la utillidad esperada de cada una de las opciones o más en general de los comportamientos dadas las restricciones. Un ejemplo claro de este tipo de mecanismos es el modelo de mínima distancia de Staddon (1980). Donde se busca minizar la distancia del punto preferido de distribución del comportamiento (free-behavior point) al coonjunto de distribuciones posibles dadas las restricciones.
Mejoramiento (Melioration).
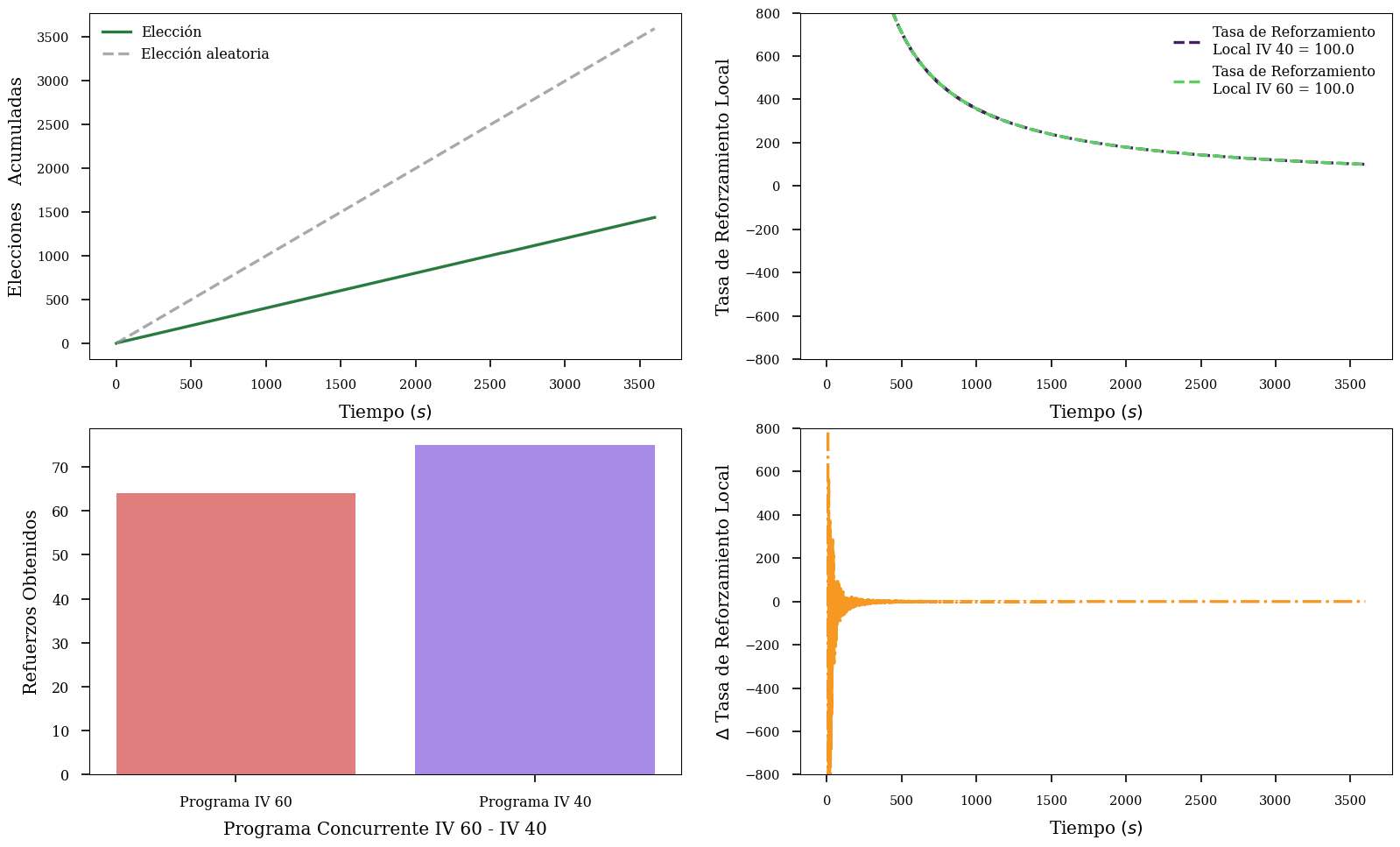
Este mecanismo se basa en la idea de que los organismos no maximizan la utilidad esperada global, sino a nivel local por medio de elegir “lo mejor de lo recientemente experimentado”. Pues se compara la tasa de reforzamiento local de cada opción. Formalmente para programas IV:
\[\text{Tasa de Reforzamiento Local}_i \equiv \frac{IV_i}{T_{i}}\]
Es decir, la tasa de reforzamiento local es la razón entre el valor esperado del programa IV y el tiempo relativo al total dedicado a explotar esa opción. Como regla de decisión Vaughan y Herrnstein proponen la siguiente regla delta:
\[ D = f(\text{Tasa de Reforzamiento Local}_I - \text{Tasa de Reforzamiento Local}_R)\]
Es decir la diferencia entre las tasas locales de las opciones IV-IV del programa concurrente, \(f(\cdot)\) en los casos más sencillos es lineal. Si la tasa de reforzamiento es menor a \(0\) se elige la opción I, en caso contrario la opción R. Se puede demostrar que esta simple regla puede llevar al equilibrio descrito por la ley de igualación.
A continuación se muestra un simulador donde podrás ver como se da este proceso dinámico de mejoramiento para programas concurrentes IV-IV.
Haz Clic para ver el Código
```{python}#@title Código de Simulación# Paqueteriasimport numpy as npimport matplotlib.pyplot as pltimport ipywidgets as wdfrom matplotlib import rcParamsdef melioration_iv(ivl, ivr, time):# Inicialización de las variables choice = np.random.choice([1, 0]) left_reward, right_reward =0, 0 reinforcement_left = [0] reinforcement_right = [0] decisions = np.empty(shape = time, dtype=np.int32) local_r = np.empty(shape = time, dtype=np.float32) local_l = np.empty(shape = time, dtype = np.float32)for second inrange(time):# IV izquierda, choice = 0 if left_reward ==0: left_reward = np.random.choice([1, 0], p = [1/ivl, 1-1/ivl])elif left_reward ==0and choice ==0: reinforcement_left.append(0)elif left_reward ==1and choice ==0: reinforcement_left.append(1) left_reward =0elif left_reward ==1and choice ==1:pass# IV derecha, choice = 1if right_reward ==0: right_reward = np.random.choice([1, 0], p = [1/ivr, 1-1/ivr])elif right_reward ==0and choice ==1: reinforcement_right.append(0)elif right_reward ==1and choice ==1: reinforcement_right.append(1) right_reward =0elif right_reward ==1and choice ==0:pass# Historial de decisiones decisions[second] = choice# Tiempo Relativo en Cada Opción relative_time_r = np.sum(decisions ==1) / time relative_time_l = np.sum(decisions ==0) / time# Tasa de Reforzamiento Localif relative_time_r ==0: local_reinforcement_r =0else: local_reinforcement_r = ivr / relative_time_rif relative_time_l ==0: local_reinforcement_l =0else: local_reinforcement_l = ivl / relative_time_l# Dinámica de la Tasa de Reforzamiento Local local_l[second] = local_reinforcement_l local_r[second] = local_reinforcement_r# Regla de decisión. delta = local_reinforcement_l - local_reinforcement_r #+ noiseif delta >0: choice =0if delta <0: choice =1if delta ==0: choice = np.random.choice([1, 0])# Sumas cumulativas Choices = np.cumsum(decisions) Reinfor_r = np.cumsum(reinforcement_right) Reinfor_l = np.cumsum(reinforcement_left) Local_rate_diff = [e1 - e2 for e1, e2 inzip(local_r,local_l)]###################################################################################################################3 plt.rcParams['font.family'] ='serif'# Grádicos fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows =2, ncols =2,figsize = (20, 12))### Plot 1 ax1.plot(Choices, ls ="-", color ="#297A3F", label ="Elección", lw =2.5) ax1.plot(range(time), ls ="--", color ="#858F94", label ="Elección aleatoria", lw =2.5, alpha =0.75) ax1.set_ylabel(r"Elecciones Acumuladas", labelpad=10, size =15) ax1.set_xlabel(r"Tiempo $(s)$", labelpad =10, size =15) ax1.legend(fontsize =12, markerscale =2, frameon =False, columnspacing =3.5) ax1.tick_params(direction='out', length =7, width =1.25 , colors='black', grid_color='black', grid_alpha=0.5, pad =10, labelsize =11)### Plot 2 ax2.plot(local_r, ls ="--", color ="#481C66", label =f"Tasa de Reforzamiento \nLocal IV {ivr} = {round(local_r[-1], 2)}", lw =2.5) ax2.plot(local_l, ls ="--", color ="#5CCE64", label =f"Tasa de Reforzamiento \nLocal IV {ivl} = {round(local_l[-1], 2)}", lw =2.5) ax2.legend(fontsize =12, markerscale =2.5, frameon =False, columnspacing =3.5) ax2.set_ylabel(r"Tasa de Reforzamiento Local", labelpad=10, size =15) ax2.set_xlabel(r"Tiempo $(s)$", labelpad =10, size =15) ax2.tick_params(direction='out', length =7, width =1.25 , colors='black', grid_color='black', grid_alpha=0.5, pad =10, labelsize =11) ax2.set_ylim(-800, 800)### Plot 3 ax3.bar(x = [f"Programa IV {ivl}", f"Programa IV {ivr}"], height = [sum(reinforcement_left), sum(reinforcement_right)], color = ["#DD7070", "#9F7FE5"], alpha =0.9) ax3.tick_params(direction='out', length =7, width =1.25 , colors='black', grid_color='black', grid_alpha=0.5, pad =10, labelsize =12) ax3.set_ylabel(r"Refuerzos Obtenidos", labelpad=10, size =15) ax3.set_xlabel(f"Programa Concurrente IV {ivl} - IV {ivr}", labelpad =10, size =15)### Plot 4 ax4.plot(Local_rate_diff, lw =2.5, ls ="-.", color ="#F69822") ax4.set_ylabel(r"$\Delta$ Tasa de Reforzamiento Local", labelpad=10, size =15) ax4.set_xlabel(r"Tiempo $(s)$", labelpad =10, size =15) ax4.tick_params(direction='out', length =7, width =1.25 , colors='black', grid_color='black', grid_alpha=0.5, pad =10, labelsize =11) ax4.set_ylim(-800, 800) plt.show()```
El simulador tiene las siguientes opciones:
IV izquierda: Representa el valor del programa IV de la opción izquierda en una caja de Skinner, el programa tiene unidades en segundos.
IV derecha: Representa el valor del programa IV de la opción derecha en una caja de Skinner, el programa tiene unidades en segundos.
Tiempo Experimental: Representa el tiempo a ser simulado, puede ser 30 min (0.5 h), 1 h (default), 1.5 h o 2 h.
Run Interact: Corre la simulación con los datos actuales.
*** Advertencia *** La idea es que las tasas de reforzamiento se iguales, a veces no puede suceder pero es por la misma estocasticidad de la simulación, sin embargo, basta con volverla a correr para que converga.
Haz Clic para ver el Código
```{python}melioration_iv(ivl =60, ivr =40, time =3600)```
Referencias
Staddon, J. E. (1979). Operant behavior as adaptation to constraint. Journal of Experimental Psychology: General, 108 (1), 48–67. https://doi.org/10.1037/0096-3445.108.1.48
Staddon, J. E. R. (1988). Quasi-Dynamic Choice Models: Melioration and Ratio in Variance. Journal of the Experimental Analysis of Behavior, 49 (2), 303–320. https://doi.org/10.1901/jeab.1988.49-303